 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Self-Attention Joint Model for Spoken Language Understanding in Situational Dialog Applications
Paper and Code
May 27, 2019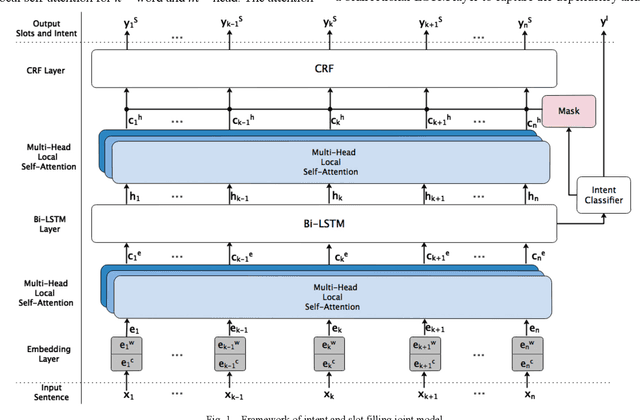
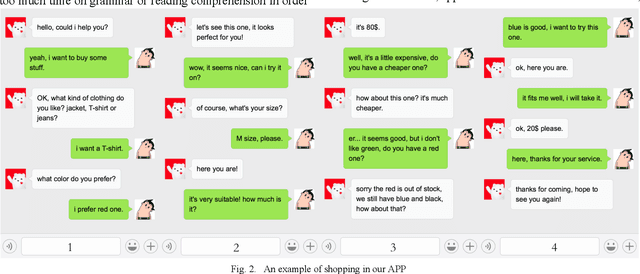

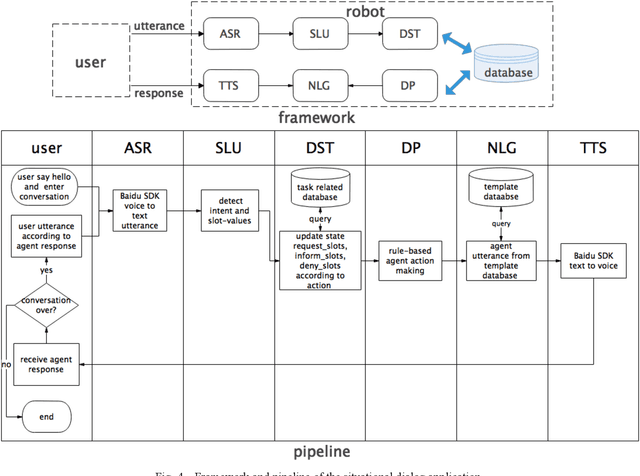
Spoken language understanding (SLU) acts as a critical component in goal-oriented dialog systems. It typically involves identifying the speakers intent and extracting semantic slots from user utterances, which are known as intent detection (ID) and slot filling (SF). SLU problem has been intensively investigated in recent years. However, these methods just constrain SF results grammatically, solve ID and SF independently, or do not fully utilize the mutual impact of the two tasks. This paper proposes a multi-head self-attention joint model with a conditional random field (CRF) layer and a prior mask. The experiments show the effectiveness of our model, as compared with state-of-the-art models. Meanwhile, online education in China has made great progress in the last few years. But there are few intelligent educational dialog applications for students to learn foreign languages. Hence, we design an intelligent dialog robot equipped with different scenario settings to help students learn communication skills.