 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIncremental Learning Using a Grow-and-Prune Paradigm with Efficient Neural Networks
Paper and Code
May 27, 2019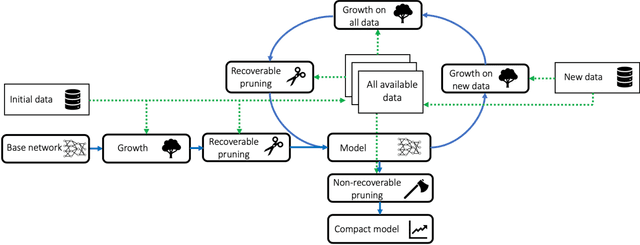

Deep neural networks (DNNs) have become a widely deployed model for numerous machine learning applications. However, their fixed architecture, substantial training cost, and significant model redundancy make it difficult to efficiently update them to accommodate previously unseen data. To solve these problems, we propose an incremental learning framework based on a grow-and-prune neural network synthesis paradigm. When new data arrive, the neural network first grows new connections based on the gradients to increase the network capacity to accommodate new data. Then, the framework iteratively prunes away connections based on the magnitude of weights to enhance network compactness, and hence recover efficiency. Finally, the model rests at a lightweight DNN that is both ready for inference and suitable for future grow-and-prune updates. The proposed framework improves accuracy, shrinks network size, and significantly reduces the additional training cost for incoming data compared to conventional approaches, such as training from scratch and network fine-tuning. For the LeNet-300-100 and LeNet-5 neural network architectures derived for the MNIST dataset, the framework reduces training cost by up to 64% (63%) and 67% (63%) compared to training from scratch (network fine-tuning), respectively. For the ResNet-18 architecture derived for the ImageNet dataset and DeepSpeech2 for the AN4 dataset, the corresponding training cost reductions against training from scratch (network fine-tunning) are 64% (60%) and 67% (62%), respectively. Our derived models contain fewer network parameters but achieve higher accuracy relative to conventional baselines.