 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Learning Over-parameterized Neural Networks: A Functional Approximation Prospective
Paper and Code
May 26, 2019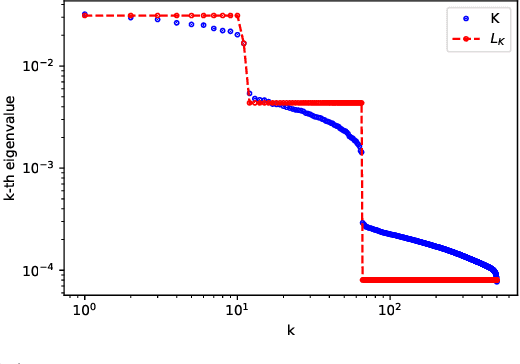
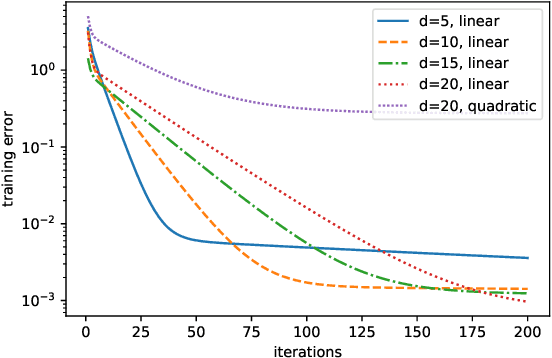
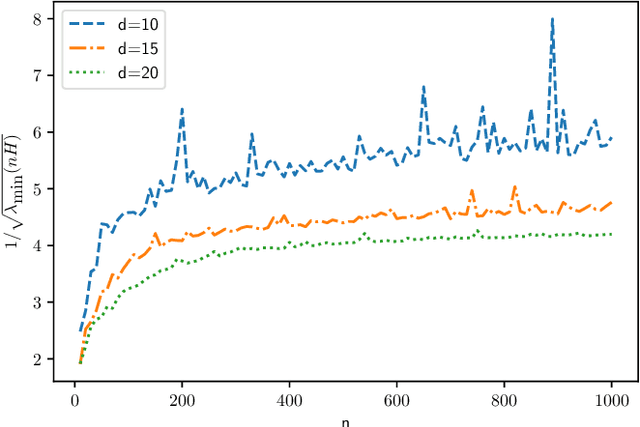
We consider training over-parameterized two-layer neural networks with Rectified Linear Unit (ReLU) using gradient descent (GD) method. Inspired by a recent line of work, we study the evolutions of the network prediction errors across GD iterations, which can be neatly described in a matrix form. It turns out that when the network is sufficiently over-parameterized, these matrices individually approximate an integral operator which is determined by the feature vector distribution $\rho$ only. Consequently, GD method can be viewed as approximately apply the powers of this integral operator on the underlying/target function $f^*$ that generates the responses/labels. We show that if $f^*$ admits a low-rank approximation with respect to the eigenspaces of this integral operator, then, even with constant stepsize, the empirical risk decreases to this low-rank approximation error at a linear rate in iteration $t$. In addition, this linear rate is determined by $f^*$ and $\rho$ only. Furthermore, if $f^*$ has zero low-rank approximation error, then $\Omega(n^2)$ network over-parameterization is enough, and the empirical risk decreases to $\Theta(1/\sqrt{n})$. We provide an application of our general results to the setting where $\rho$ is the uniform distribution on the spheres and $f^*$ is a polynomial.