 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdversarial Distillation for Ordered Top-k Attacks
Paper and Code
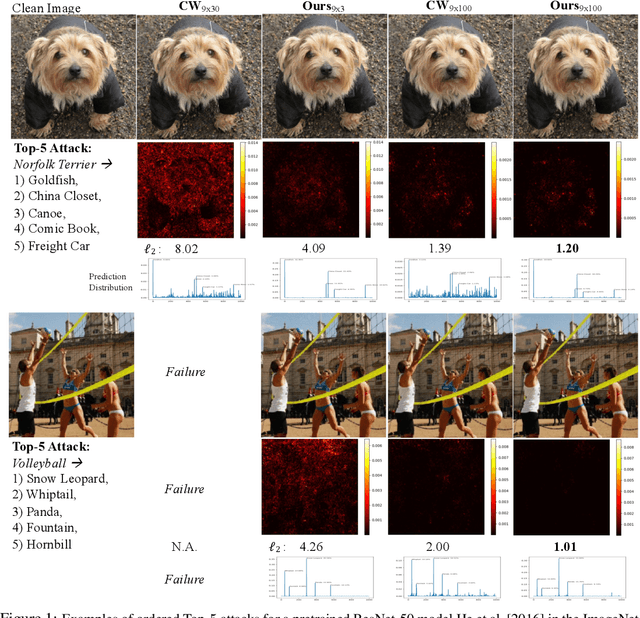

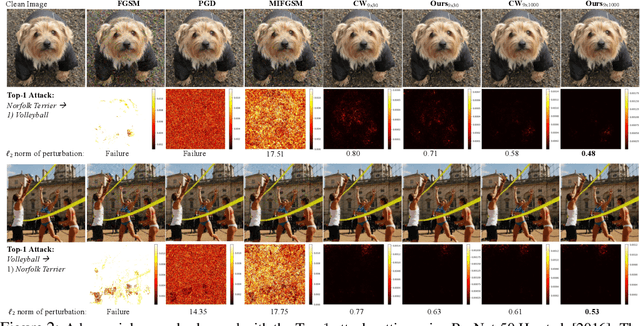
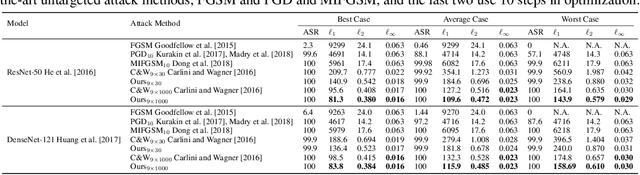
Deep Neural Networks (DNNs) are vulnerable to adversarial attacks, especially white-box targeted attacks. One scheme of learning attacks is to design a proper adversarial objective function that leads to the imperceptible perturbation for any test image (e.g., the Carlini-Wagner (C&W) method). Most methods address targeted attacks in the Top-1 manner. In this paper, we propose to learn ordered Top-k attacks (k>= 1) for image classification tasks, that is to enforce the Top-k predicted labels of an adversarial example to be the k (randomly) selected and ordered labels (the ground-truth label is exclusive). To this end, we present an adversarial distillation framework: First, we compute an adversarial probability distribution for any given ordered Top-k targeted labels with respect to the ground-truth of a test image. Then, we learn adversarial examples by minimizing the Kullback-Leibler (KL) divergence together with the perturbation energy penalty, similar in spirit to the network distillation method. We explore how to leverage label semantic similarities in computing the targeted distributions, leading to knowledge-oriented attacks. In experiments, we thoroughly test Top-1 and Top-5 attacks in the ImageNet-1000 validation dataset using two popular DNNs trained with clean ImageNet-1000 train dataset, ResNet-50 and DenseNet-121. For both models, our proposed adversarial distillation approach outperforms the C&W method in the Top-1 setting, as well as other baseline methods. Our approach shows significant improvement in the Top-5 setting against a strong modified C&W method.