 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Micro-Objective Perspective of Reinforcement Learning
Paper and Code
Jun 12, 2019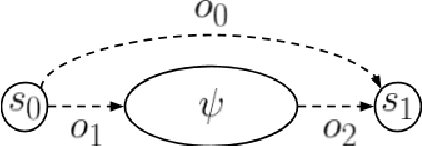
The standard reinforcement learning (RL) formulation considers the expectation of the (discounted) cumulative reward. This is limiting in applications where we are concerned with not only the expected performance, but also the distribution of the performance. In this paper, we introduce micro-objective reinforcement learning --- an alternative RL formalism that overcomes this issue. In this new formulation, a RL task is specified by a set of micro-objectives, which are constructs that specify the desirability or undesirability of events. In addition, micro-objectives allow prior knowledge in the form of temporal abstraction to be incorporated into the global RL objective. The generality of this formalism, and its relations to single/multi-objective RL, and hierarchical RL are discussed.