 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConvergence and Margin of Adversarial Training on Separable Data
Paper and Code
May 22, 2019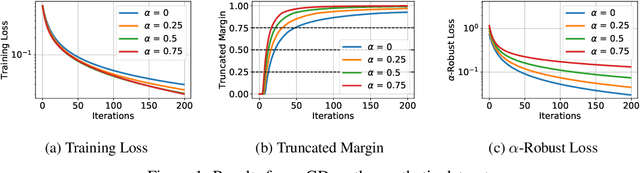
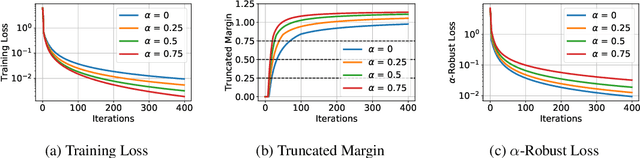
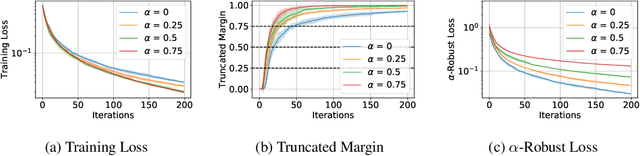
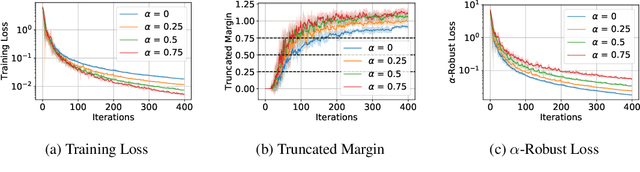
Adversarial training is a technique for training robust machine learning models. To encourage robustness, it iteratively computes adversarial examples for the model, and then re-trains on these examples via some update rule. This work analyzes the performance of adversarial training on linearly separable data, and provides bounds on the number of iterations required for large margin. We show that when the update rule is given by an arbitrary empirical risk minimizer, adversarial training may require exponentially many iterations to obtain large margin. However, if gradient or stochastic gradient update rules are used, only polynomially many iterations are required to find a large-margin separator. By contrast, without the use of adversarial examples, gradient methods may require exponentially many iterations to achieve large margin. Our results are derived by showing that adversarial training with gradient updates minimizes a robust version of the empirical risk at a $\mathcal{O}(\ln(t)^2/t)$ rate, despite non-smoothness. We corroborate our theory empirically.