 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSample Efficient Text Summarization Using a Single Pre-Trained Transformer
Paper and Code
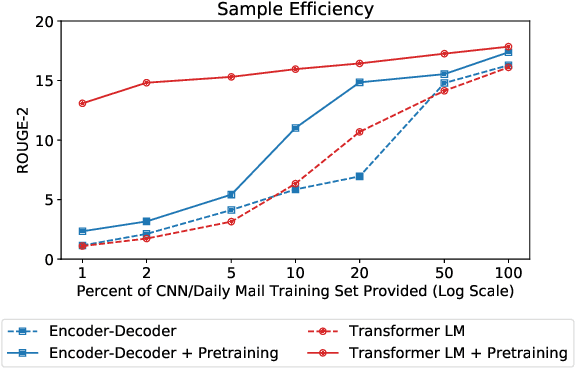
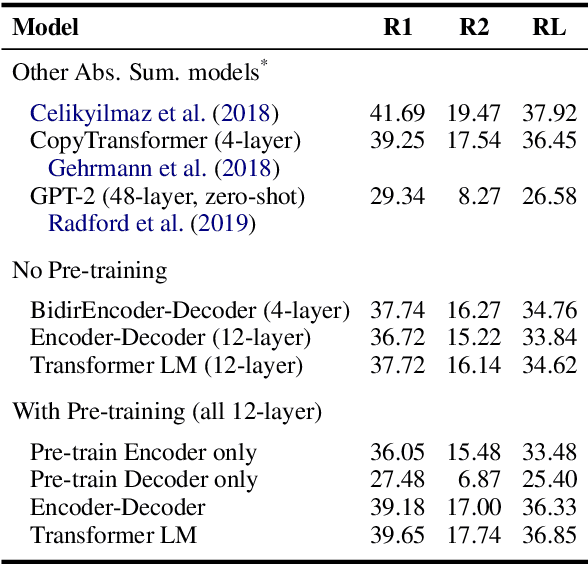
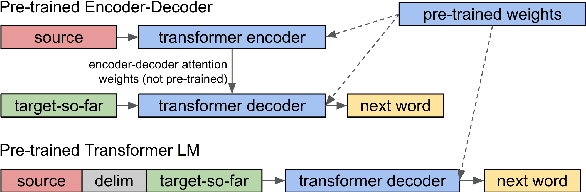

Language model (LM) pre-training has resulted in impressive performance and sample efficiency on a variety of language understanding tasks. However, it remains unclear how to best use pre-trained LMs for generation tasks such as abstractive summarization, particularly to enhance sample efficiency. In these sequence-to-sequence settings, prior work has experimented with loading pre-trained weights into the encoder and/or decoder networks, but used non-pre-trained encoder-decoder attention weights. We instead use a pre-trained decoder-only network, where the same Transformer LM both encodes the source and generates the summary. This ensures that all parameters in the network, including those governing attention over source states, have been pre-trained before the fine-tuning step. Experiments on the CNN/Daily Mail dataset show that our pre-trained Transformer LM substantially improves over pre-trained Transformer encoder-decoder networks in limited-data settings. For instance, it achieves 13.1 ROUGE-2 using only 1% of the training data (~3000 examples), while pre-trained encoder-decoder models score 2.3 ROUGE-2.