 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScalable Gromov-Wasserstein Learning for Graph Partitioning and Matching
Paper and Code
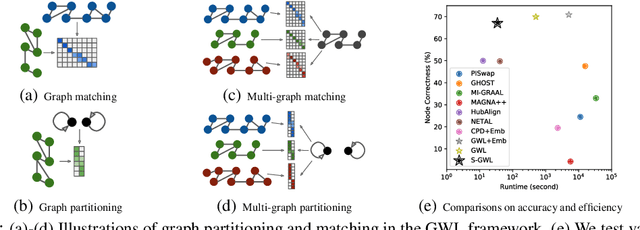
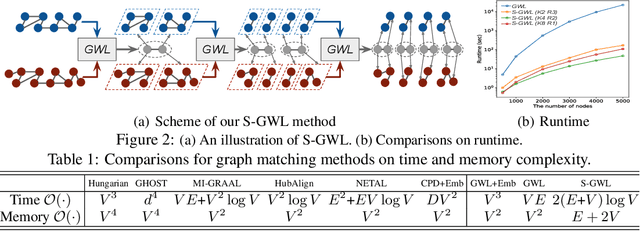
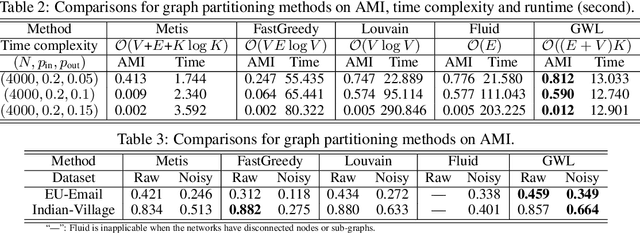
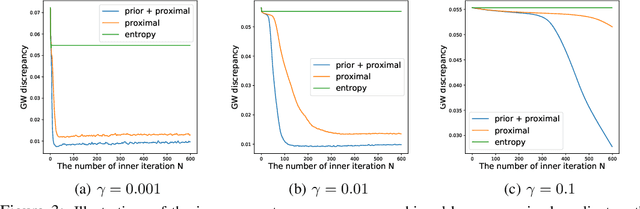
We propose a scalable Gromov-Wasserstein learning (S-GWL) method and establish a novel and theoretically-supported paradigm for large-scale graph analysis. The proposed method is based on the fact that Gromov-Wasserstein discrepancy is a pseudometric on graphs. Given two graphs, the optimal transport associated with their Gromov-Wasserstein discrepancy provides the correspondence between their nodes and achieves graph matching. When one of the graphs has isolated but self-connected nodes ($i.e.$, a disconnected graph), the optimal transport indicates the clustering structure of the other graph and achieves graph partitioning. Using this concept, we extend our method to multi-graph partitioning and matching by learning a Gromov-Wasserstein barycenter graph for multiple observed graphs; the barycenter graph plays the role of the disconnected graph, and since it is learned, so is the clustering. Our method combines a recursive $K$-partition mechanism with a regularized proximal gradient algorithm, whose time complexity is $\mathcal{O}(K(E+V)\log_K V)$ for graphs with $V$ nodes and $E$ edges. To our knowledge, our method is the first attempt to make Gromov-Wasserstein discrepancy applicable to large-scale graph analysis and unify graph partitioning and matching into the same framework. It outperforms state-of-the-art graph partitioning and matching methods, achieving a trade-off between accuracy and efficiency.