 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStochastic approximation with cone-contractive operators: Sharp $\ell_\infty$-bounds for $Q$-learning
Paper and Code
May 15, 2019
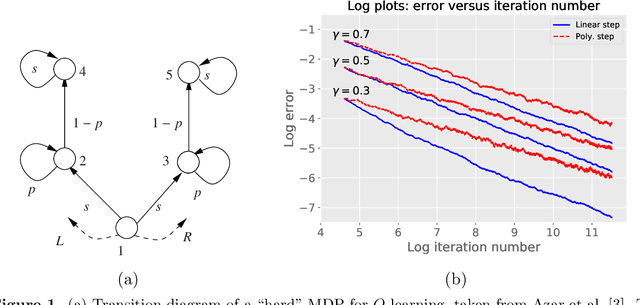
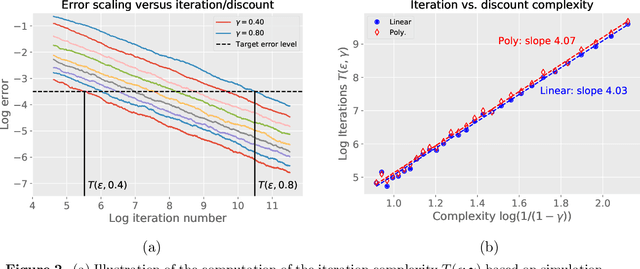
Motivated by the study of $Q$-learning algorithms in reinforcement learning, we study a class of stochastic approximation procedures based on operators that satisfy monotonicity and quasi-contractivity conditions with respect to an underlying cone. We prove a general sandwich relation on the iterate error at each time, and use it to derive non-asymptotic bounds on the error in terms of a cone-induced gauge norm. These results are derived within a deterministic framework, requiring no assumptions on the noise. We illustrate these general bounds in application to synchronous $Q$-learning for discounted Markov decision processes with discrete state-action spaces, in particular by deriving non-asymptotic bounds on the $\ell_\infty$-norm for a range of stepsizes. These results are the sharpest known to date, and we show via simulation that the dependence of our bounds cannot be improved in a worst-case sense. These results show that relative to a model-based $Q$-iteration, the $\ell_\infty$-based sample complexity of $Q$-learning is suboptimal in terms of the discount factor $\gamma$.