 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutonomous Penetration Testing using Reinforcement Learning
Paper and Code
May 15, 2019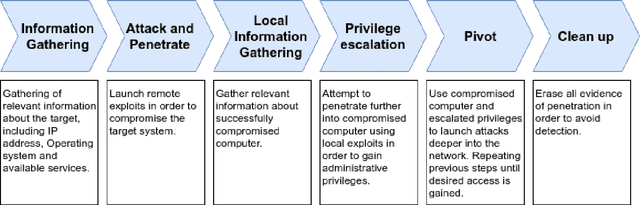
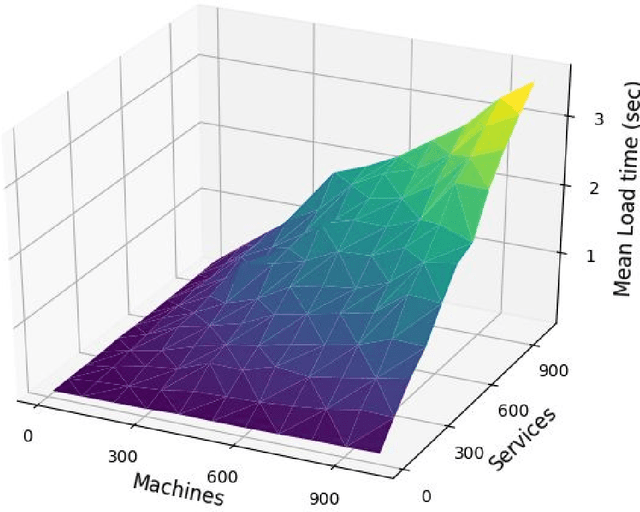
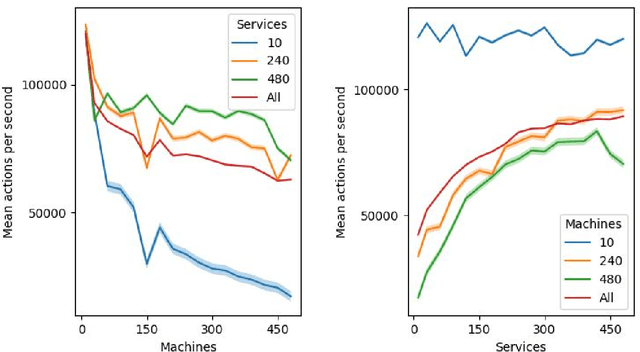
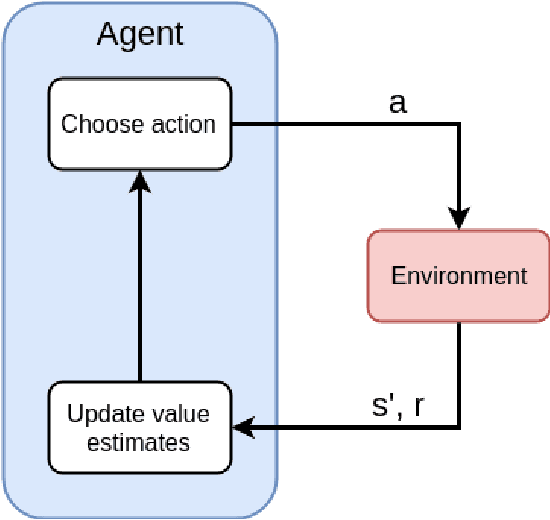
Penetration testing (pentesting) involves performing a controlled attack on a computer system in order to assess it's security. Although an effective method for testing security, pentesting requires highly skilled practitioners and currently there is a growing shortage of skilled cyber security professionals. One avenue for alleviating this problem is automate the pentesting process using artificial intelligence techniques. Current approaches to automated pentesting have relied on model-based planning, however the cyber security landscape is rapidly changing making maintaining up-to-date models of exploits a challenge. This project investigated the application of model-free Reinforcement Learning (RL) to automated pentesting. Model-free RL has the key advantage over model-based planning of not requiring a model of the environment, instead learning the best policy through interaction with the environment. We first designed and built a fast, low compute simulator for training and testing autonomous pentesting agents. We did this by framing pentesting as a Markov Decision Process with the known configuration of the network as states, the available scans and exploits as actions, the reward determined by the value of machines on the network. We then used this simulator to investigate the application of model-free RL to pentesting. We tested the standard Q-learning algorithm using both tabular and neural network based implementations. We found that within the simulated environment both tabular and neural network implementations were able to find optimal attack paths for a range of different network topologies and sizes without having a model of action behaviour. However, the implemented algorithms were only practical for smaller networks and numbers of actions. Further work is needed in developing scalable RL algorithms and testing these algorithms in larger and higher fidelity environments.