 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust Neural Network Training using Periodic Sampling over Model Weights
Paper and Code
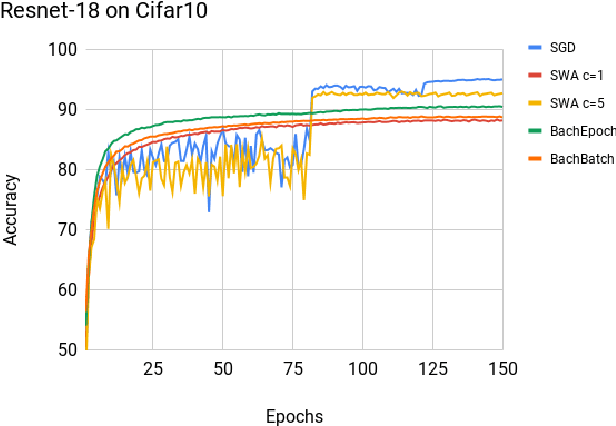
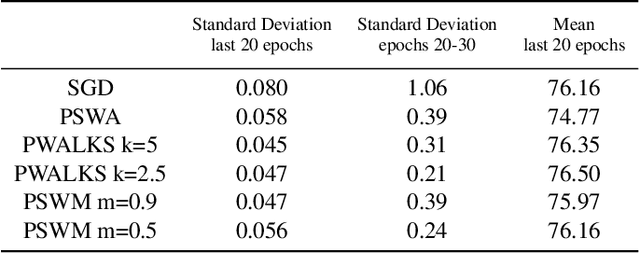
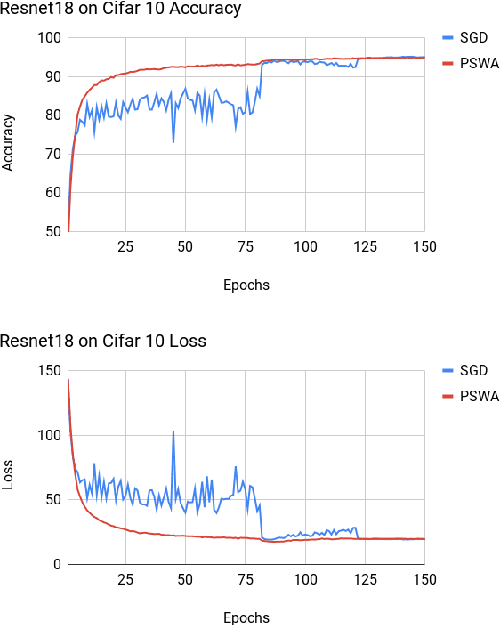
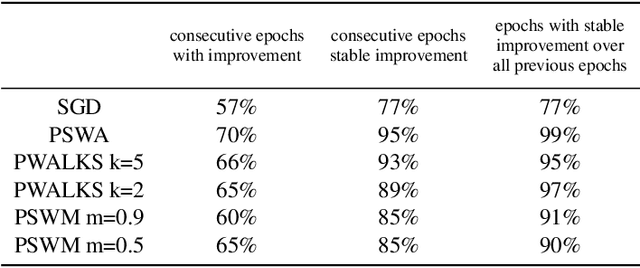
Deep neural networks provide best-in-class performance for a number of computer vision problems. However, training these networks is computationally intensive and requires fine-tuning various hyperparameters. In addition, performance swings widely as the network converges making it hard to decide when to stop training. In this paper, we introduce a trio of techniques (PSWA, PWALKS, and PSWM) centered around periodic sampling of model weights that provide consistent and more robust convergence on a variety of vision problems (classification, detection, segmentation) and gradient update methods (vanilla SGD, Momentum, Adam) with marginal additional computation time. Our techniques use existing optimal training policies but converge in a less volatile fashion with performance improvements that are approximately monotonic. Our analysis of the loss surface shows that these techniques also produce minima that are deeper and wider than those found by SGD.