 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpatially Constrained Generative Adversarial Networks for Conditional Image Generation
Paper and Code
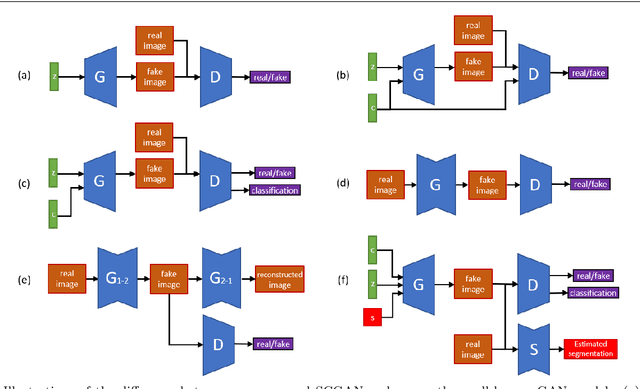
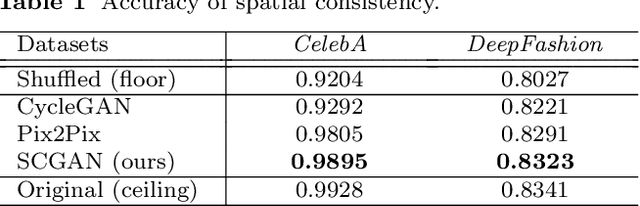
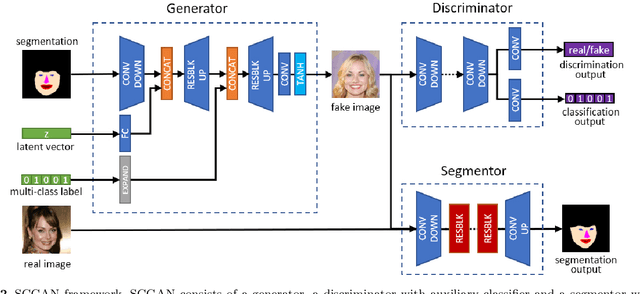
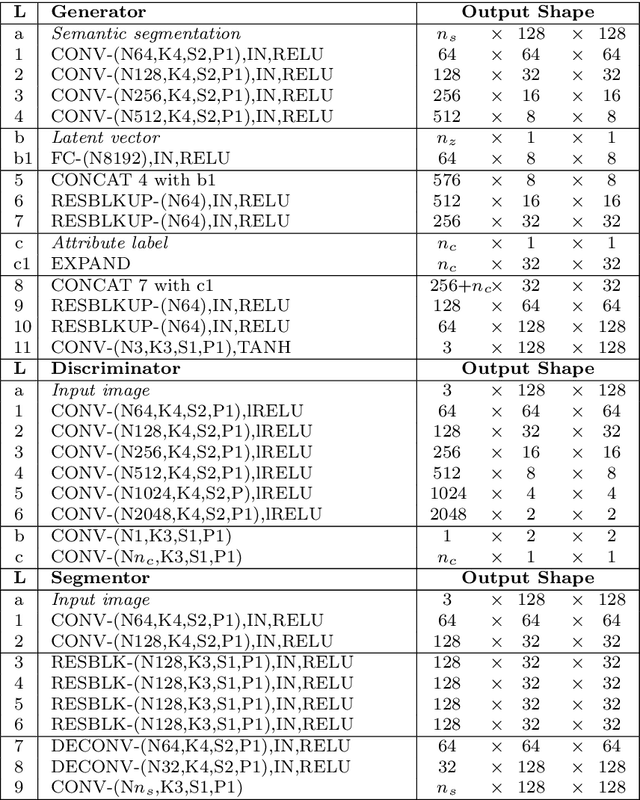
Image generation has raised tremendous attention in both academic and industrial areas, especially for the conditional and target-oriented image generation, such as criminal portrait and fashion design. Although the current studies have achieved preliminary results along this direction, they always focus on class labels as the condition where spatial contents are randomly generated from latent vectors. Edge details are usually blurred since spatial information is difficult to preserve. In light of this, we propose a novel Spatially Constrained Generative Adversarial Network (SCGAN), which decouples the spatial constraints from the latent vector and makes these constraints feasible as additional controllable signals. To enhance the spatial controllability, a generator network is specially designed to take a semantic segmentation, a latent vector and an attribute-level label as inputs step by step. Besides, a segmentor network is constructed to impose spatial constraints on the generator. Experimentally, we provide both visual and quantitative results on CelebA and DeepFashion datasets, and demonstrate that the proposed SCGAN is very effective in controlling the spatial contents as well as generating high-quality images.