 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZero-Shot Audio Classification Based on Class Label Embeddings
Paper and Code
May 06, 2019
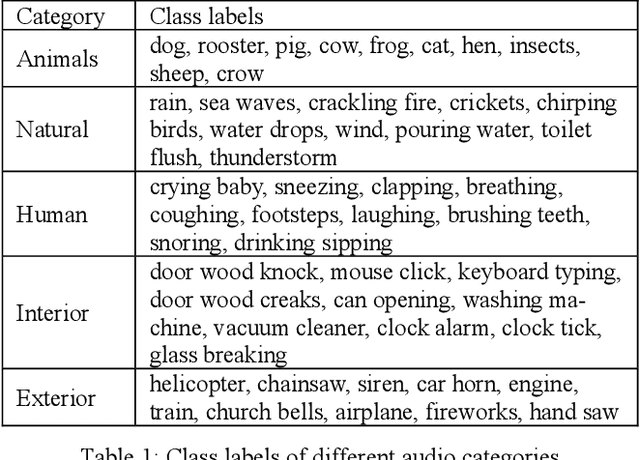
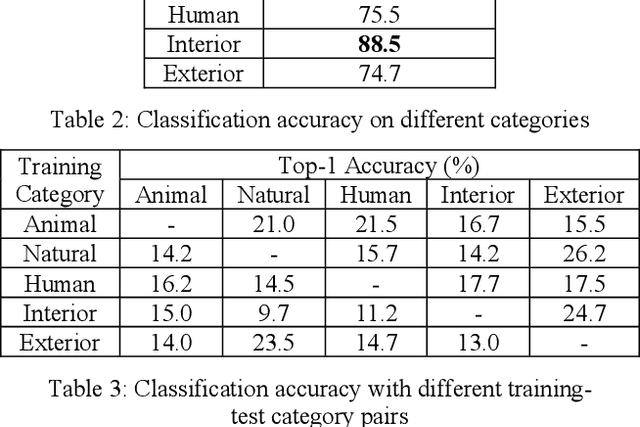
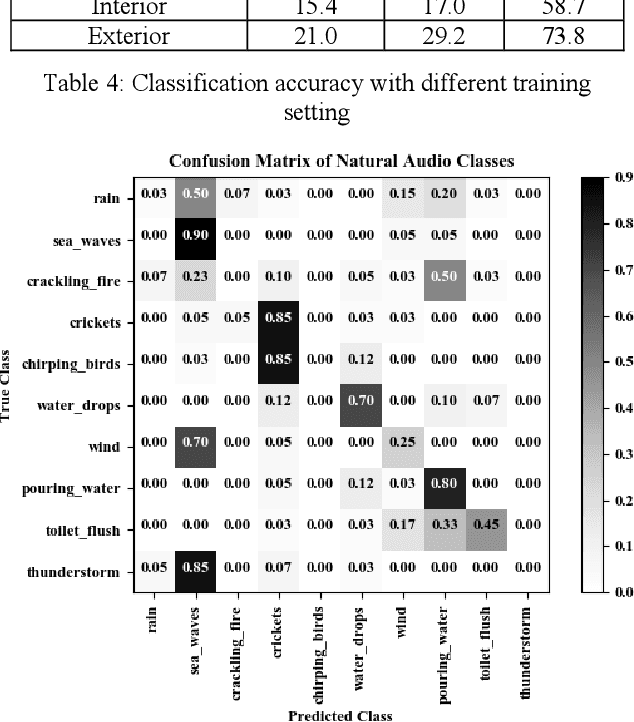
This paper proposes a zero-shot learning approach for audio classification based on the textual information about class labels without any audio samples from target classes. We propose an audio classification system built on the bilinear model, which takes audio feature embeddings and semantic class label embeddings as input, and measures the compatibility between an audio feature embedding and a class label embedding. We use VGGish to extract audio feature embeddings from audio recordings. We treat textual labels as semantic side information of audio classes, and use Word2Vec to generate class label embeddings. Results on the ESC-50 dataset show that the proposed system can perform zero-shot audio classification with small training dataset. It can achieve accuracy (26 % on average) better than random guess (10 %) on each audio category. Particularly, it reaches up to 39.7 % for the category of natural audio classes.