 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransformers with convolutional context for ASR
Paper and Code
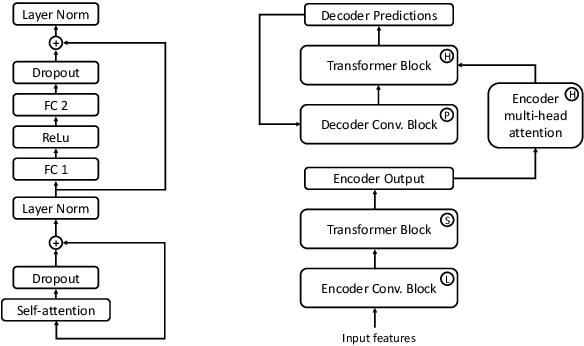
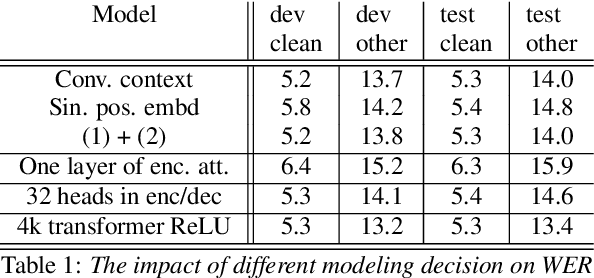
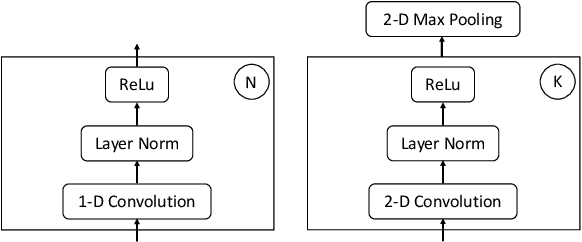
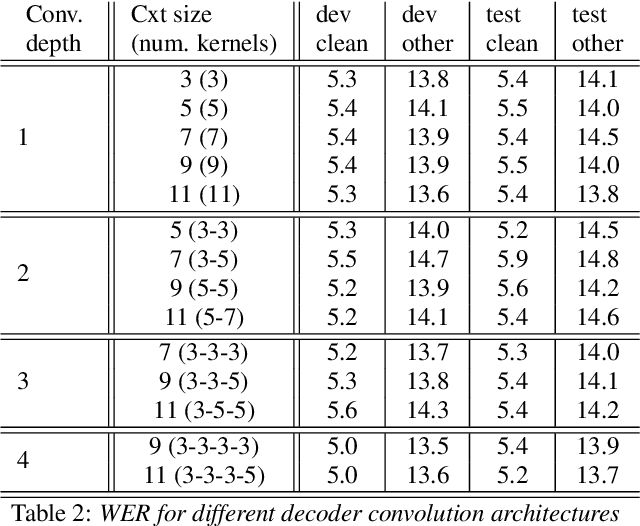
The recent success of transformer networks for neural machine translation and other NLP tasks has led to a surge in research work trying to apply it for speech recognition. Recent efforts studied key research questions around ways of combining positional embedding with speech features, and stability of optimization for large scale learning of transformer networks. In this paper, we propose replacing the sinusoidal positional embedding for transformers with convolutionally learned input representations. These contextual representations provide subsequent transformer blocks with relative positional information needed for discovering long-range relationships between local concepts. The proposed system has favorable optimization characteristics where our reported results are produced with fixed learning rate of 1.0 and no warmup steps. The proposed model reduces the word error rate (WER) by 12% and 16% relative to previously published work on Librispeech "dev other" and "test other" subsets respectively, when no extra LM text is provided. Full code to reproduce our results will be available online at the time of publication.