 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRawNet: Fast End-to-End Neural Vocoder
Paper and Code
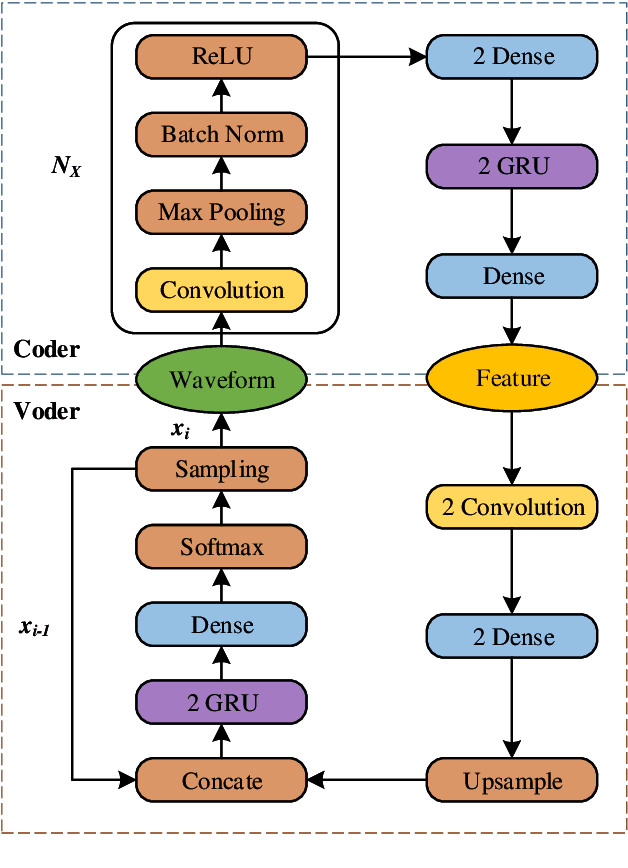
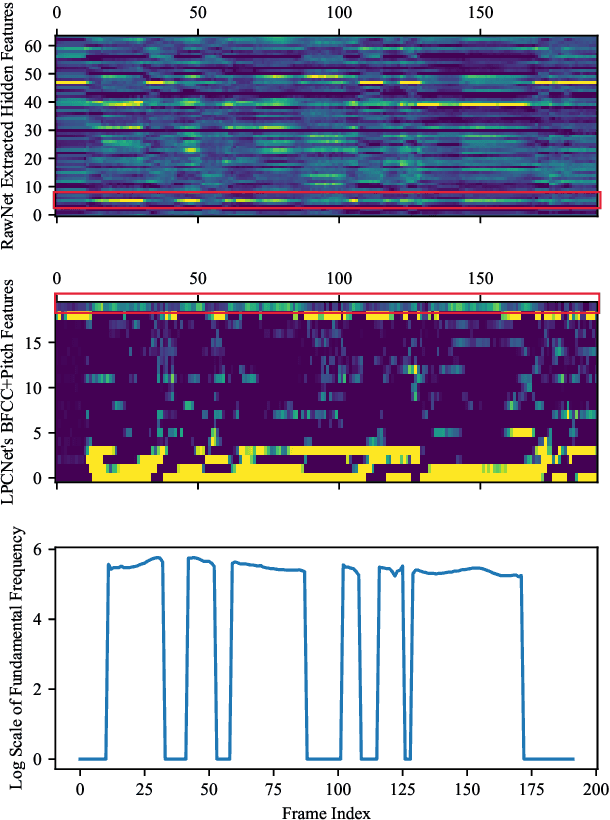
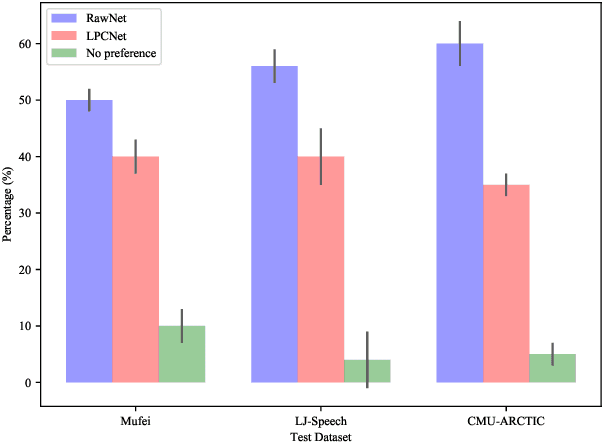
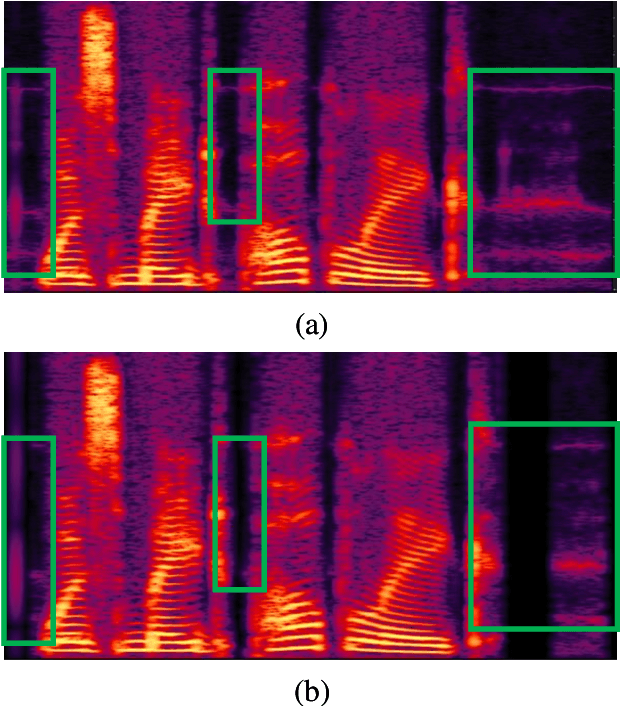
Neural networks based vocoders have recently demonstrated the powerful ability to synthesize high quality speech. These models usually generate samples by conditioning on some spectrum features, such as Mel-spectrum. However, these features are extracted by using speech analysis module including some processing based on the human knowledge. In this work, we proposed RawNet, a truly end-to-end neural vocoder, which use a coder network to learn the higher representation of signal, and an autoregressive voder network to generate speech sample by sample. The coder and voder together act like an auto-encoder network, and could be jointly trained directly on raw waveform without any human-designed features. The experiments on the Copy-Synthesis tasks show that RawNet can achieve the comparative synthesized speech quality with LPCNet, with a smaller model architecture and faster speech generation at the inference step.