 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeText-based Depression Detection: What Triggers An Alert
Paper and Code
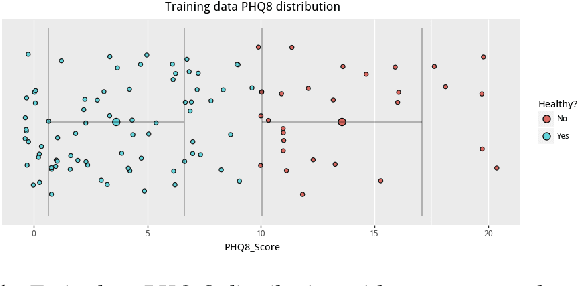
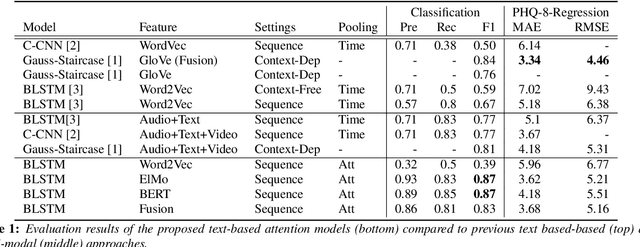
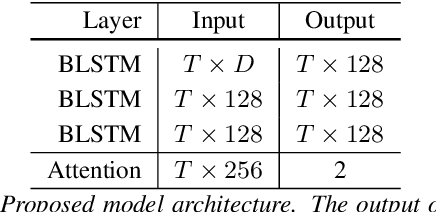
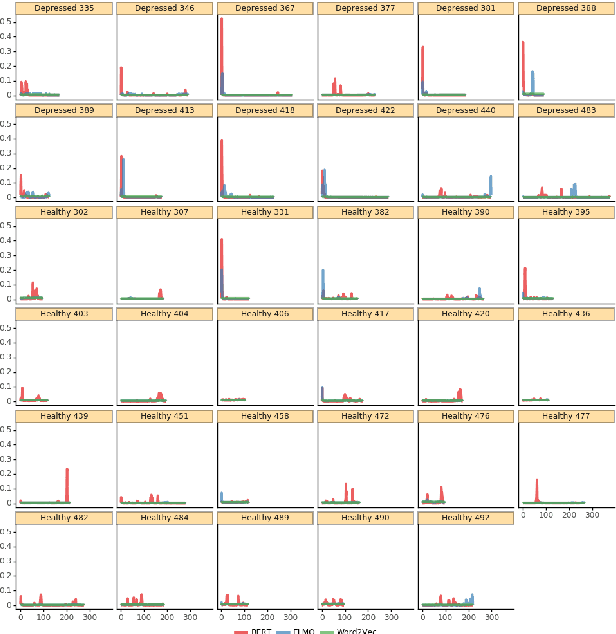
Recent advances in automatic depression detection mostly derive from modality fusion and deep learning methods. However multi-modal approaches insert significant difficulty in data collection phase while deep learning methods' opaqueness lowers its credibility. This current work proposes a text-based multi-task BLSTM model with pretrained word embeddings. Our method outputs depression presence results as well as predicted severity score, culminating a state-of-the-art F1 score of 0.87, outperforming previous multi-modal studies. We also achieve the lowest RMSE compared with currently available text-based approaches. Further, by utilizing a per time step attention mechanism we analyse the sentences/words that contribute most in predicting the depressed state. Surprisingly, `unmeaningful' words/paralinguistic information such as `um' and `uh' are the indicators to our model when making a depression prediction. It is for the first time revealed that fillers in a conversation trigger a depression alert for a deep learning model.