 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFLightNNs: Lightweight Quantized Deep Neural Networks for Fast and Accurate Inference
Paper and Code
Apr 05, 2019
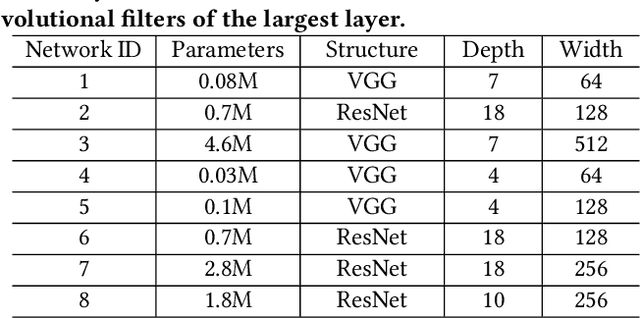
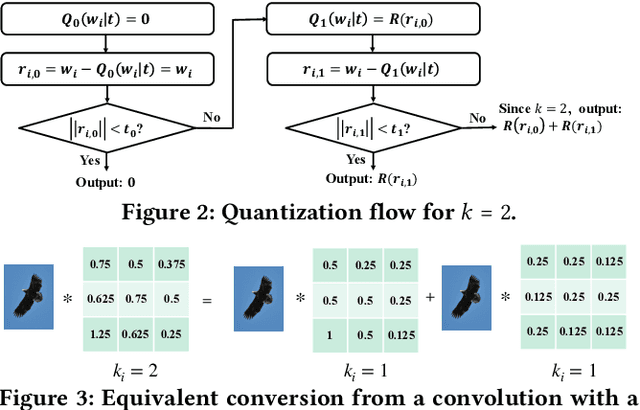
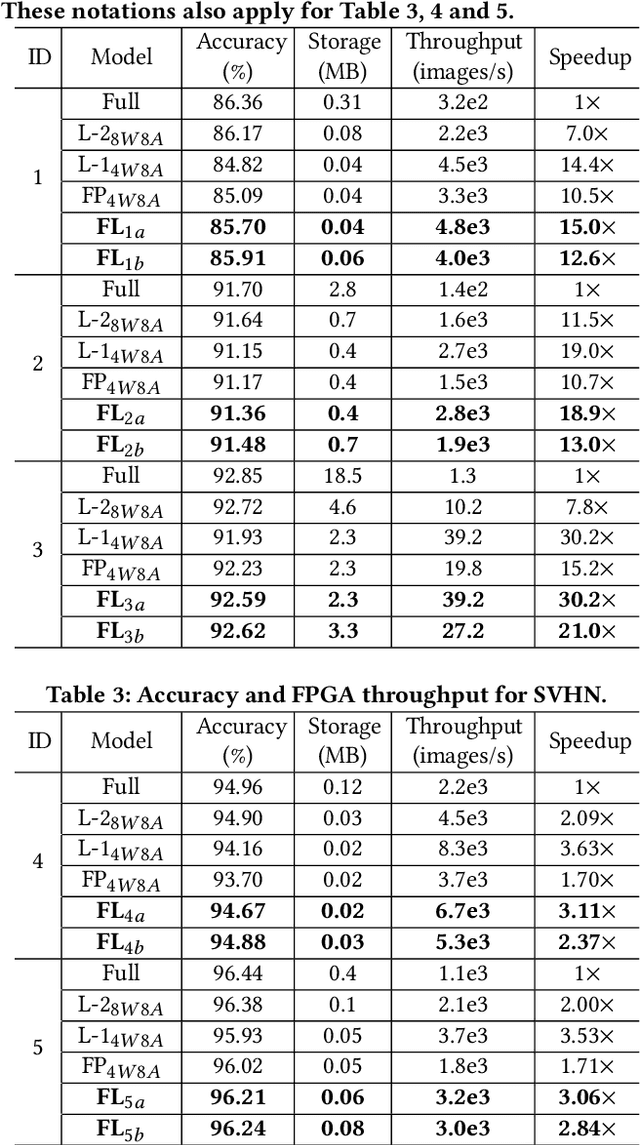
To improve the throughput and energy efficiency of Deep Neural Networks (DNNs) on customized hardware, lightweight neural networks constrain the weights of DNNs to be a limited combination (denoted as $k\in\{1,2\}$) of powers of 2. In such networks, the multiply-accumulate operation can be replaced with a single shift operation, or two shifts and an add operation. To provide even more design flexibility, the $k$ for each convolutional filter can be optimally chosen instead of being fixed for every filter. In this paper, we formulate the selection of $k$ to be differentiable, and describe model training for determining $k$-based weights on a per-filter basis. Over 46 FPGA-design experiments involving eight configurations and four data sets reveal that lightweight neural networks with a flexible $k$ value (dubbed FLightNNs) fully utilize the hardware resources on Field Programmable Gate Arrays (FPGAs), our experimental results show that FLightNNs can achieve 2$\times$ speedup when compared to lightweight NNs with $k=2$, with only 0.1\% accuracy degradation. Compared to a 4-bit fixed-point quantization, FLightNNs achieve higher accuracy and up to 2$\times$ inference speedup, due to their lightweight shift operations. In addition, our experiments also demonstrate that FLightNNs can achieve higher computational energy efficiency for ASIC implementation.