 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutoregressive Policies for Continuous Control Deep Reinforcement Learning
Paper and Code
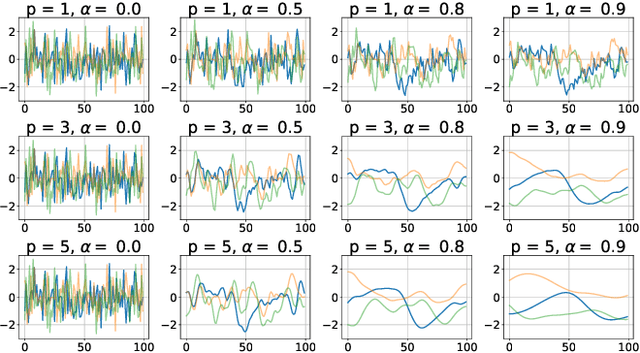
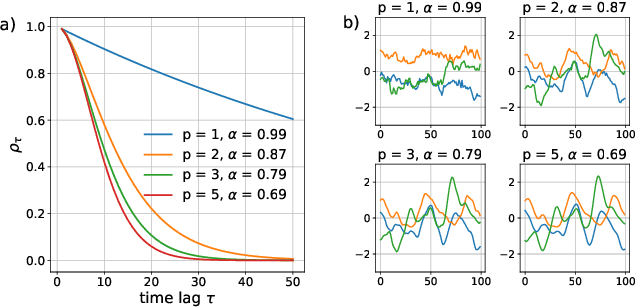
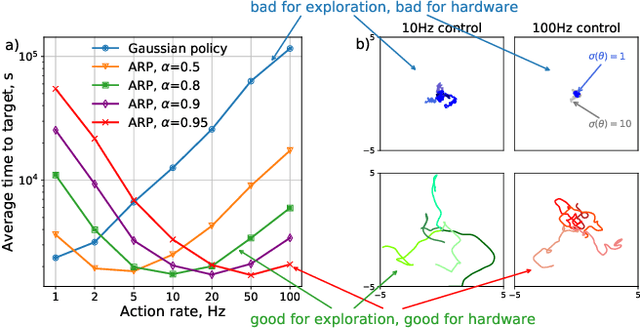
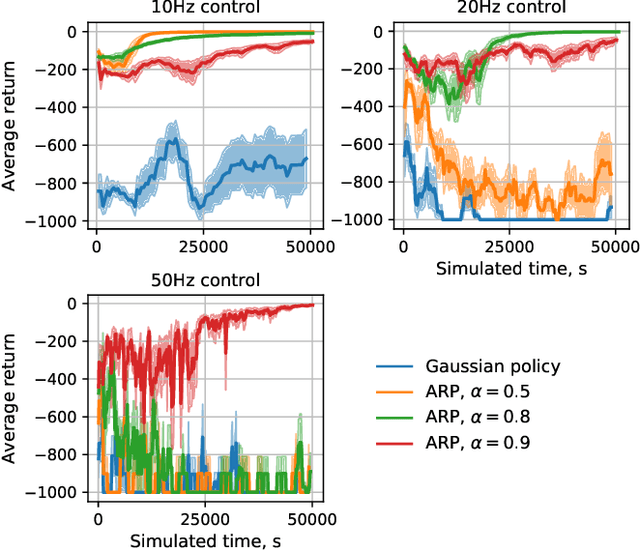
Reinforcement learning algorithms rely on exploration to discover new behaviors, which is typically achieved by following a stochastic policy. In continuous control tasks, policies with a Gaussian distribution have been widely adopted. Gaussian exploration however does not result in smooth trajectories that generally correspond to safe and rewarding behaviors in practical tasks. In addition, Gaussian policies do not result in an effective exploration of an environment and become increasingly inefficient as the action rate increases. This contributes to a low sample efficiency often observed in learning continuous control tasks. We introduce a family of stationary autoregressive (AR) stochastic processes to facilitate exploration in continuous control domains. We show that proposed processes possess two desirable features: subsequent process observations are temporally coherent with continuously adjustable degree of coherence, and the process stationary distribution is standard normal. We derive an autoregressive policy (ARP) that implements such processes maintaining the standard agent-environment interface. We show how ARPs can be easily used with the existing off-the-shelf learning algorithms. Empirically we demonstrate that using ARPs results in improved exploration and sample efficiency in both simulated and real world domains, and, furthermore, provides smooth exploration trajectories that enable safe operation of robotic hardware.