Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData Poisoning against Differentially-Private Learners: Attacks and Defenses
Paper and Code
Mar 23, 2019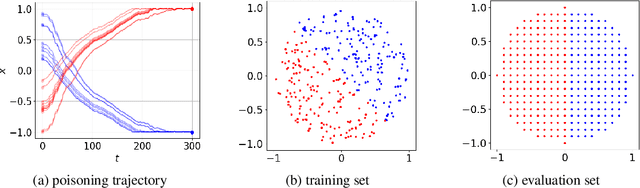
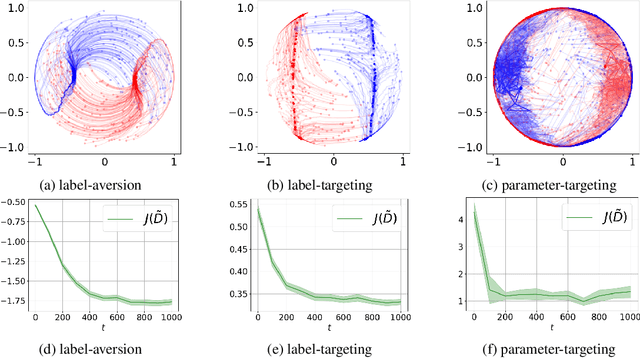
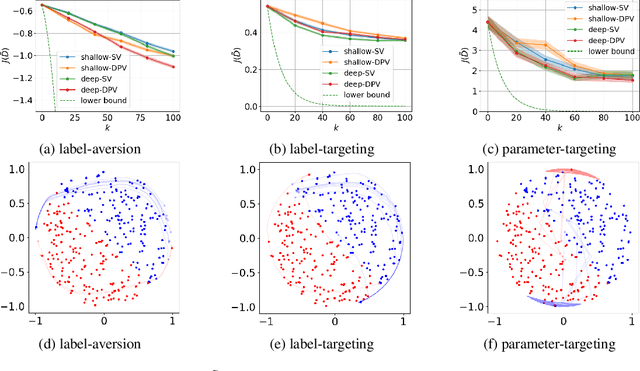
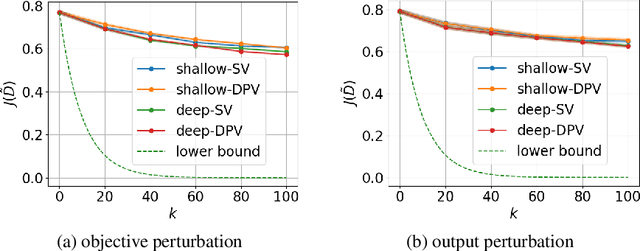
Data poisoning attacks aim to manipulate the model produced by a learning algorithm by adversarially modifying the training set. We consider differential privacy as a defensive measure against this type of attack. We show that such learners are resistant to data poisoning attacks when the adversary is only able to poison a small number of items. However, this protection degrades as the adversary poisons more data. To illustrate, we design attack algorithms targeting objective and output perturbation learners, two standard approaches to differentially-private machine learning. Experiments show that our methods are effective when the attacker is allowed to poison sufficiently many training items.
View paper on