 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmpirical Evaluations of Seed Set Selection Strategies for Predictive Coding
Paper and Code
Mar 21, 2019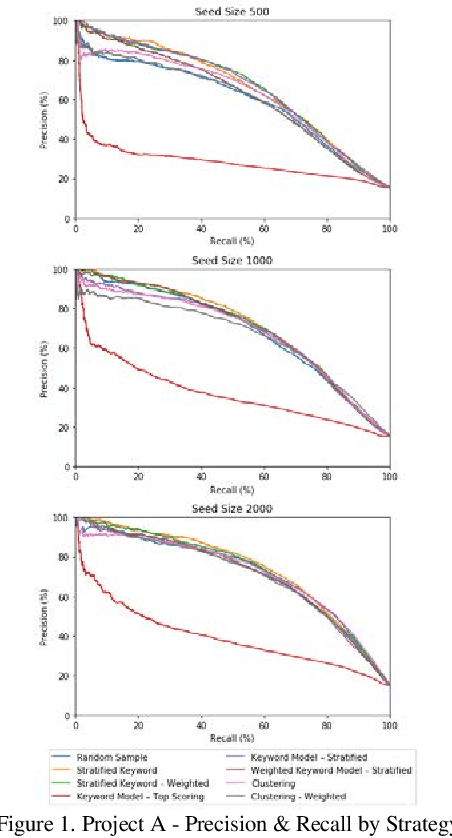
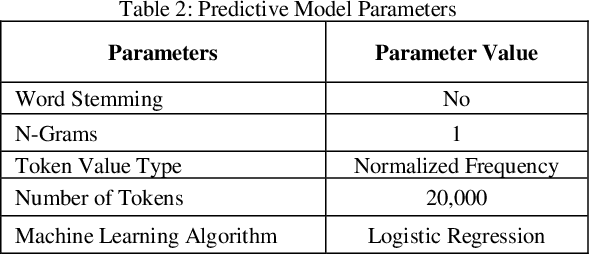
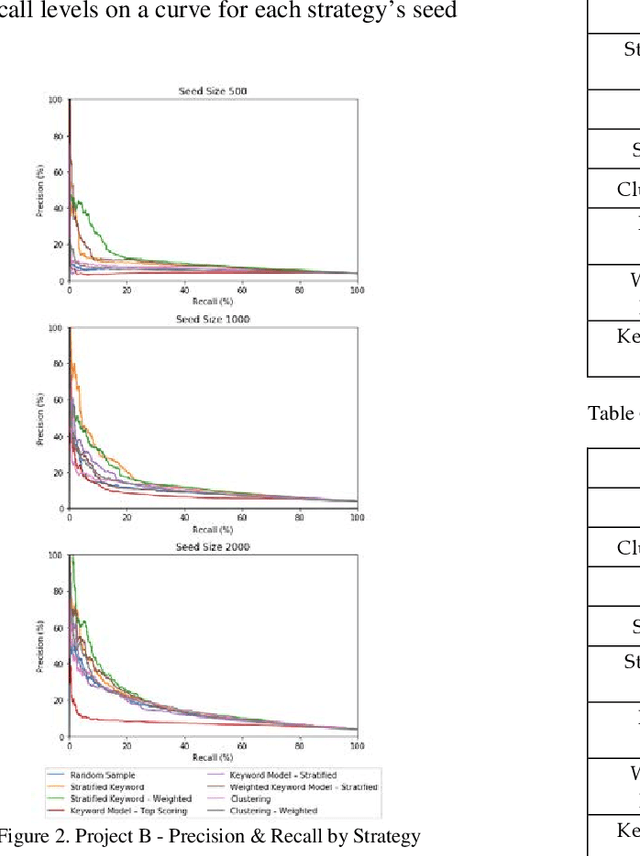
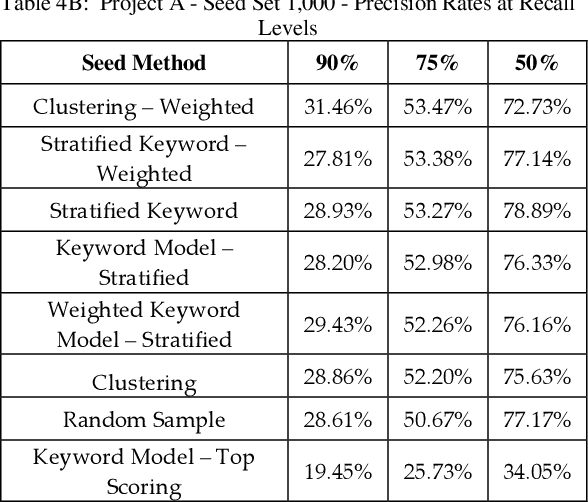
Training documents have a significant impact on the performance of predictive models in the legal domain. Yet, there is limited research that explores the effectiveness of the training document selection strategy - in particular, the strategy used to select the seed set, or the set of documents an attorney reviews first to establish an initial model. Since there is limited research on this important component of predictive coding, the authors of this paper set out to identify strategies that consistently perform well. Our research demonstrated that the seed set selection strategy can have a significant impact on the precision of a predictive model. Enabling attorneys with the results of this study will allow them to initiate the most effective predictive modeling process to comb through the terabytes of data typically present in modern litigation. This study used documents from four actual legal cases to evaluate eight different seed set selection strategies. Attorneys can use the results contained within this paper to enhance their approach to predictive coding.