 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInterpreting Neural Networks Using Flip Points
Paper and Code
Mar 21, 2019
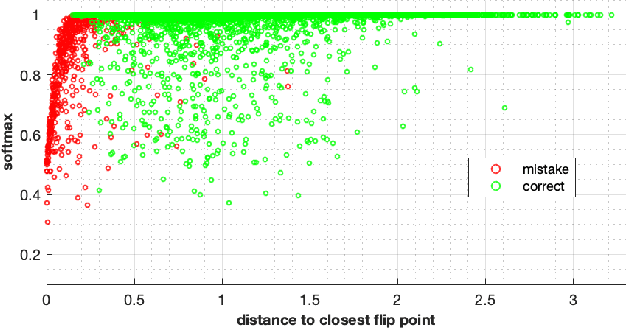
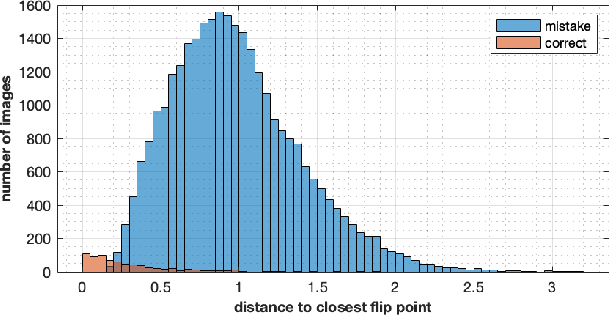
Neural networks have been criticized for their lack of easy interpretation, which undermines confidence in their use for important applications. Here, we introduce a novel technique, interpreting a trained neural network by investigating its flip points. A flip point is any point that lies on the boundary between two output classes: e.g. for a neural network with a binary yes/no output, a flip point is any input that generates equal scores for "yes" and "no". The flip point closest to a given input is of particular importance, and this point is the solution to a well-posed optimization problem. This paper gives an overview of the uses of flip points and how they are computed. Through results on standard datasets, we demonstrate how flip points can be used to provide detailed interpretation of the output produced by a neural network. Moreover, for a given input, flip points enable us to measure confidence in the correctness of outputs much more effectively than softmax score. They also identify influential features of the inputs, identify bias, and find changes in the input that change the output of the model. We show that distance between an input and the closest flip point identifies the most influential points in the training data. Using principal component analysis (PCA) and rank-revealing QR factorization (RR-QR), the set of directions from each training input to its closest flip point provides explanations of how a trained neural network processes an entire dataset: what features are most important for classification into a given class, which features are most responsible for particular misclassifications, how an adversary might fool the network, etc. Although we investigate flip points for neural networks, their usefulness is actually model-agnostic.