 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding Sparse JL for Feature Hashing
Paper and Code
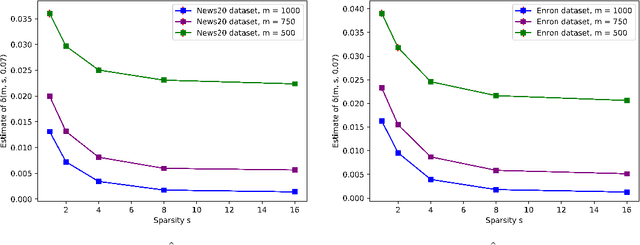
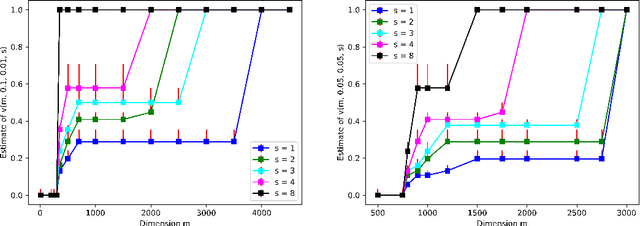
Feature hashing and more general projection schemes are commonly used in machine learning to reduce the dimensionality of feature vectors. The goal is to efficiently project a high-dimensional feature vector living in $\mathbb{R}^n$ into a lower-dimensional space $\mathbb{R}^m$, while approximately preserving Euclidean norm. These schemes can be constructed using sparse random projections, for example using a sparse Johnson-Lindenstrauss (JL) transform. In practice, feature vectors often have a low $\ell_\infty$-to-$\ell_2$ norm ratio, and for this restricted set of vectors, many sparse JL-based schemes can achieve the norm-preserving objective with smaller dimension $m$ than is necessary for the scheme on the full space $\mathbb{R}^n$. A line of work introduced by Weinberger et. al (ICML '09) analyzes the sparse JL transform with one nonzero entry per column, which is a standard feature hashing scheme. Recently, Freksen, Kamma, and Larsen (NIPS '18) closed this line of work by proving an essentially tight tradeoff between $\ell_\infty$-to-$\ell_2$ norm ratio, distortion, failure probability, and dimension $m$ for this feature hashing scheme. We study more general projection schemes that are constructed using sparse JL transforms permitted to have more than one (but still a small fraction of) nonzero entries per column. Our main result is an essentially tight tradeoff between $\ell_\infty$-to-$\ell_2$ norm ratio, distortion, failure probability, and dimension $m$ for a general sparsity $s$, that generalizes the result of Freksen et. al. We also connect our result to the sparse JL literature by showing that it implies lower bounds on dimension-sparsity tradeoffs that essentially match upper bounds by Cohen (SODA '16). Moreover, our proof introduces a new perspective on bounding moments of certain random variables, that could be useful in other settings in theoretical computer science.