 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAccelerating Training of Deep Neural Networks with a Standardization Loss
Paper and Code
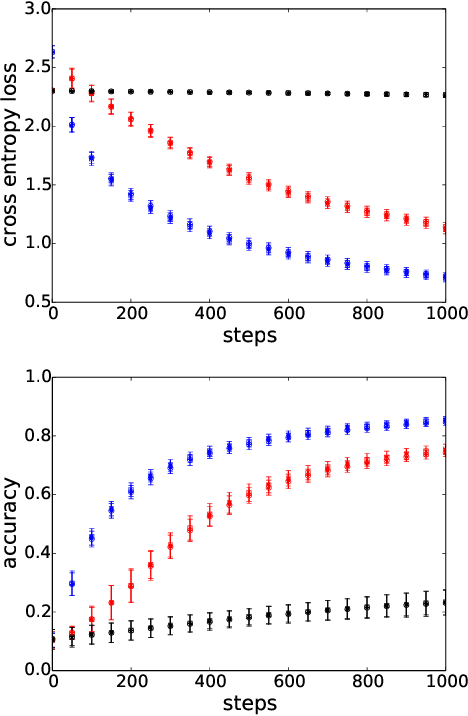
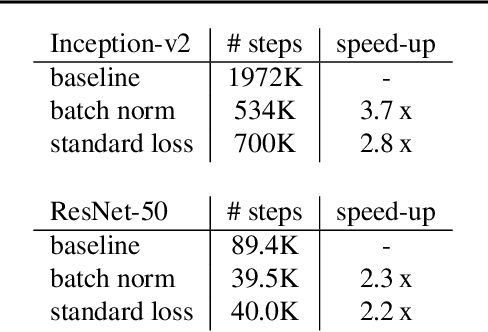
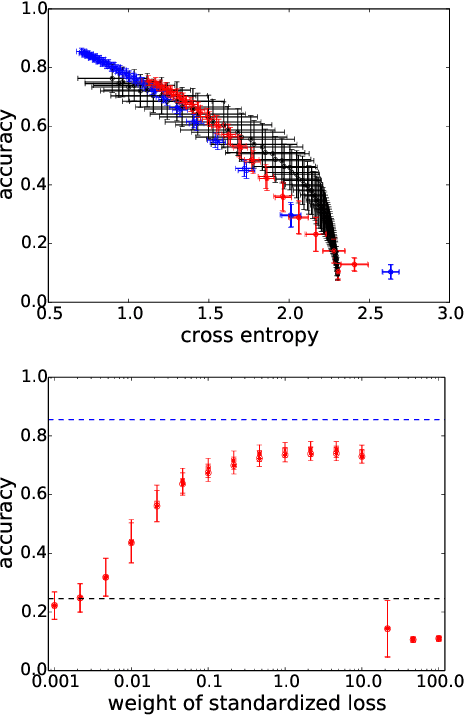
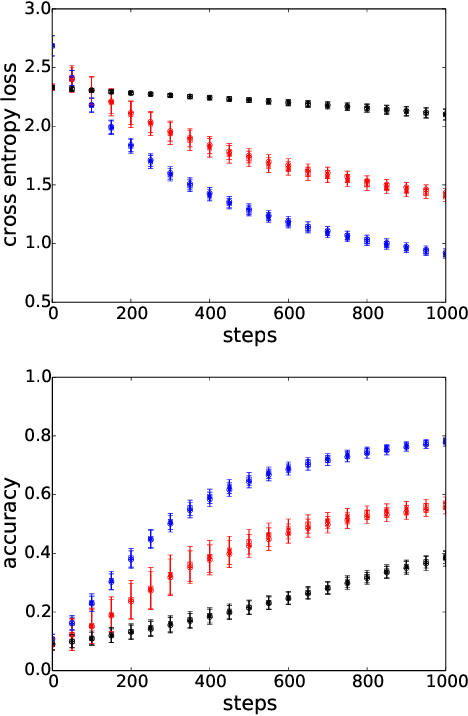
A significant advance in accelerating neural network training has been the development of normalization methods, permitting the training of deep models both faster and with better accuracy. These advances come with practical challenges: for instance, batch normalization ties the prediction of individual examples with other examples within a batch, resulting in a network that is heavily dependent on batch size. Layer normalization and group normalization are data-dependent and thus must be continually used, even at test-time. To address the issues that arise from using explicit normalization techniques, we propose to replace existing normalization methods with a simple, secondary objective loss that we term a standardization loss. This formulation is flexible and robust across different batch sizes and surprisingly, this secondary objective accelerates learning on the primary training objective. Because it is a training loss, it is simply removed at test-time, and no further effort is needed to maintain normalized activations. We find that a standardization loss accelerates training on both small- and large-scale image classification experiments, works with a variety of architectures, and is largely robust to training across different batch sizes.