 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNovel and Efficient Approximations for Zero-One Loss of Linear Classifiers
Paper and Code
Feb 28, 2019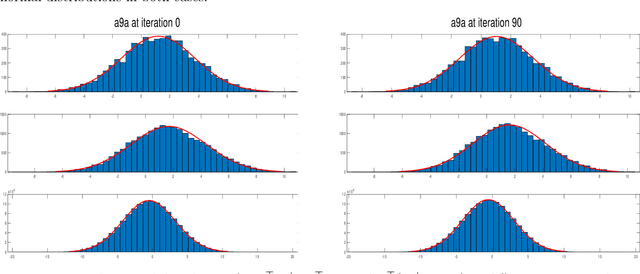
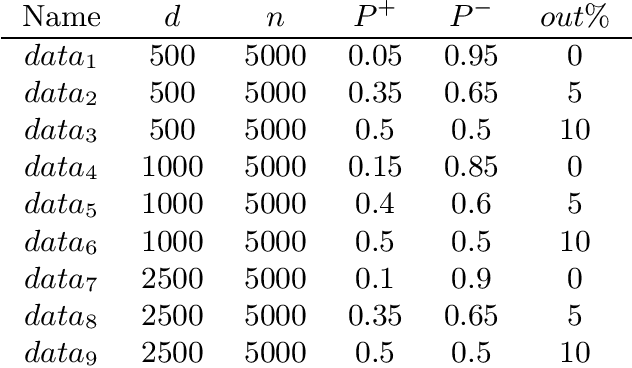
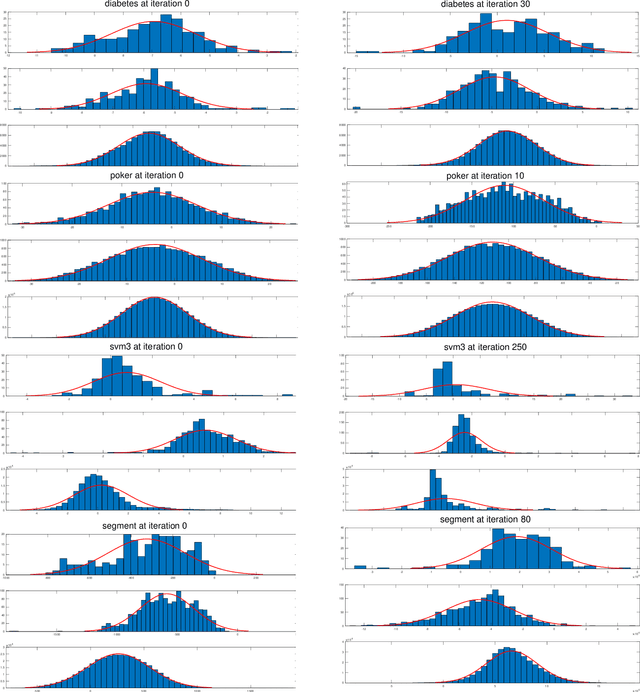
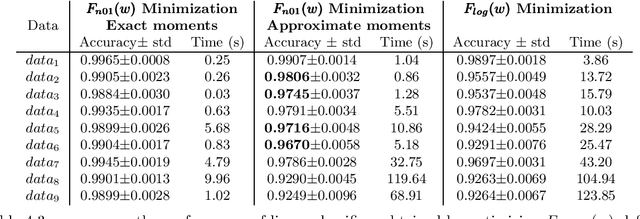
The predictive quality of machine learning models is typically measured in terms of their (approximate) expected prediction accuracy or the so-called Area Under the Curve (AUC). Minimizing the reciprocals of these measures are the goals of supervised learning. However, when the models are constructed by the means of empirical risk minimization (ERM), surrogate functions such as the logistic loss or hinge loss are optimized instead. In this work, we show that in the case of linear predictors, the expected error and the expected ranking loss can be effectively approximated by smooth functions whose closed form expressions and those of their first (and second) order derivatives depend on the first and second moments of the data distribution, which can be precomputed. Hence, the complexity of an optimization algorithm applied to these functions does not depend on the size of the training data. These approximation functions are derived under the assumption that the output of the linear classifier for a given data set has an approximately normal distribution. We argue that this assumption is significantly weaker than the Gaussian assumption on the data itself and we support this claim by demonstrating that our new approximation is quite accurate on data sets that are not necessarily Gaussian. We present computational results that show that our proposed approximations and related optimization algorithms can produce linear classifiers with similar or better test accuracy or AUC, than those obtained using state-of-the-art approaches, in a fraction of the time.