 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge3D High-Resolution Cardiac Segmentation Reconstruction from 2D Views using Conditional Variational Autoencoders
Paper and Code
Feb 28, 2019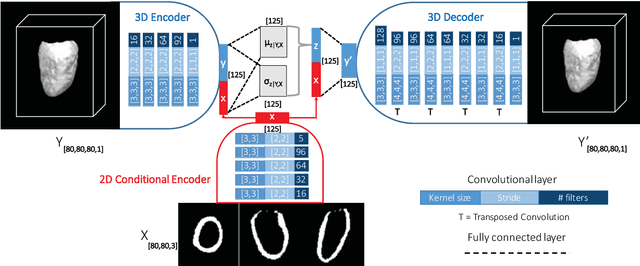
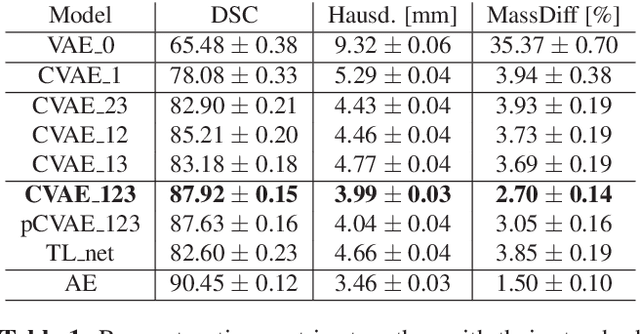
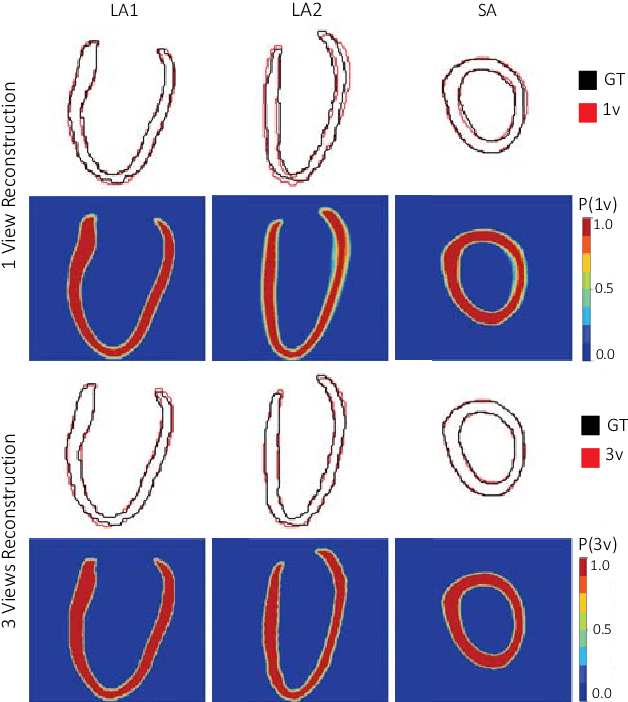
Accurate segmentation of heart structures imaged by cardiac MR is key for the quantitative analysis of pathology. High-resolution 3D MR sequences enable whole-heart structural imaging but are time-consuming, expensive to acquire and they often require long breath holds that are not suitable for patients. Consequently, multiplanar breath-hold 2D cine sequences are standard practice but are disadvantaged by lack of whole-heart coverage and low through-plane resolution. To address this, we propose a conditional variational autoencoder architecture able to learn a generative model of 3D high-resolution left ventricular (LV) segmentations which is conditioned on three 2D LV segmentations of one short-axis and two long-axis images. By only employing these three 2D segmentations, our model can efficiently reconstruct the 3D high-resolution LV segmentation of a subject. When evaluated on 400 unseen healthy volunteers, our model yielded an average Dice score of $87.92 \pm 0.15$ and outperformed competing architectures.