 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnalyzing Deep Neural Networks with Symbolic Propagation: Towards Higher Precision and Faster Verification
Paper and Code
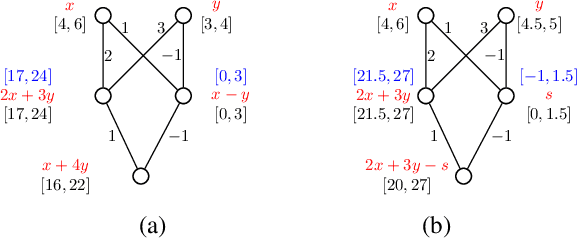
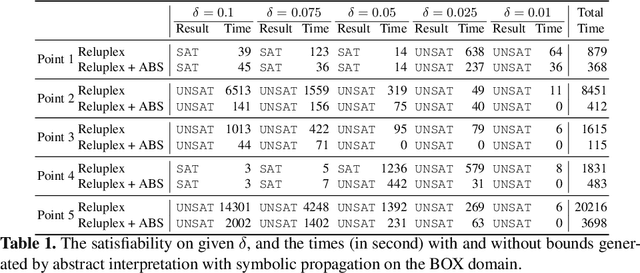
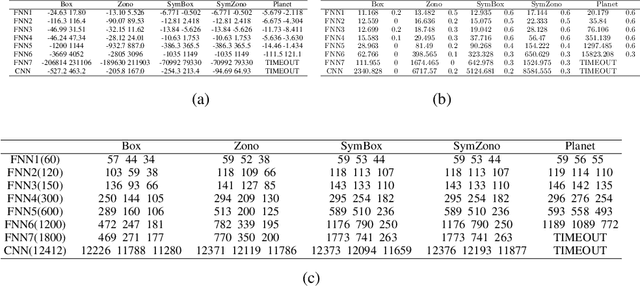
Deep neural networks (DNNs) have been shown lack of robustness for the vulnerability of their classification to small perturbations on the inputs. This has led to safety concerns of applying DNNs to safety-critical domains. Several verification approaches have been developed to automatically prove or disprove safety properties of DNNs. However, these approaches suffer from either the scalability problem, i.e., only small DNNs can be handled, or the precision problem, i.e., the obtained bounds are loose. This paper improves on a recent proposal of analyzing DNNs through the classic abstract interpretation technique, by a novel symbolic propagation technique. More specifically, the values of neurons are represented symbolically and propagated forwardly from the input layer to the output layer, on top of abstract domains. We show that our approach can achieve significantly higher precision and thus can prove more properties than using only abstract domains. Moreover, we show that the bounds derived from our approach on the hidden neurons, when applied to a state-of-the-art SMT based verification tool, can improve its performance. We implement our approach into a software tool and validate it over a few DNNs trained on benchmark datasets such as MNIST, etc.