 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Multilingual Sentence Embedding using Bi-directional Dual Encoder with Additive Margin Softmax
Paper and Code
Feb 22, 2019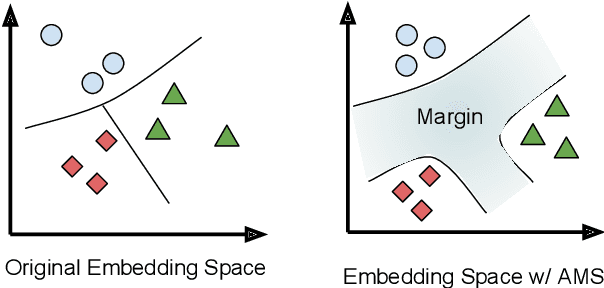

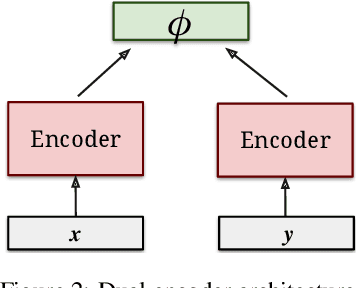

In this paper, we present an approach to learn multilingual sentence embeddings using a bi-directional dual-encoder with additive margin softmax. The embeddings are able to achieve state-of-the-art results on the United Nations (UN) parallel corpus retrieval task. In all the languages tested, the system achieves P@1 of 86% or higher. We use pairs retrieved by our approach to train NMT models that achieve similar performance to models trained on gold pairs. We explore simple document-level embeddings constructed by averaging our sentence embeddings. On the UN document-level retrieval task, document embeddings achieve around 97% on P@1 for all experimented language pairs. Lastly, we evaluate the proposed model on the BUCC mining task. The learned embeddings with raw cosine similarity scores achieve competitive results compared to current state-of-the-art models, and with a second-stage scorer we achieve a new state-of-the-art level on this task.