 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeeply Supervised Multimodal Attentional Translation Embeddings for Visual Relationship Detection
Paper and Code
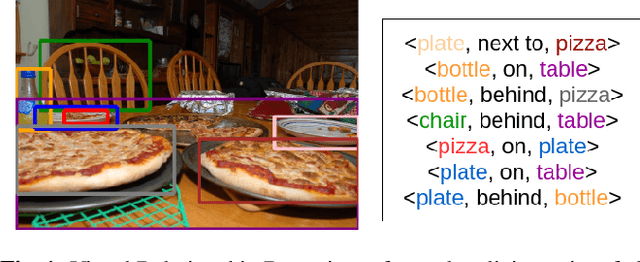
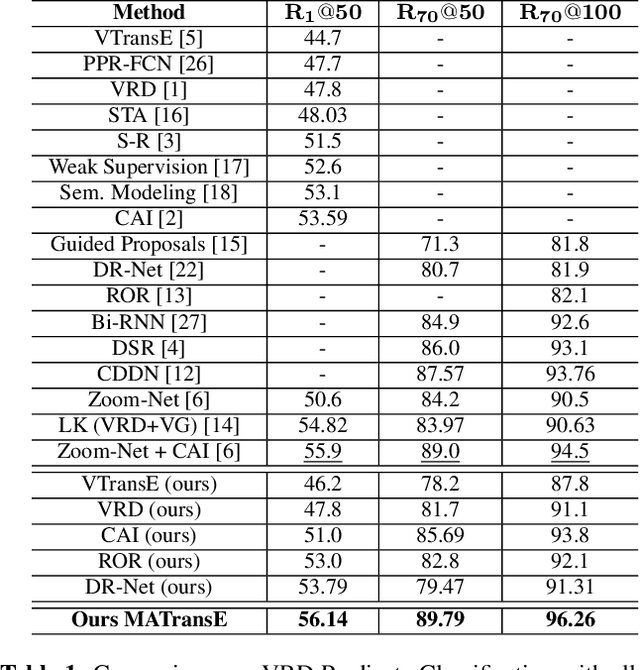
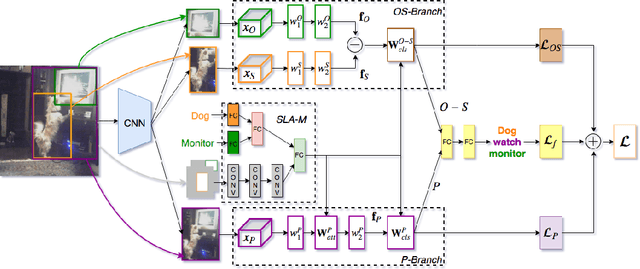
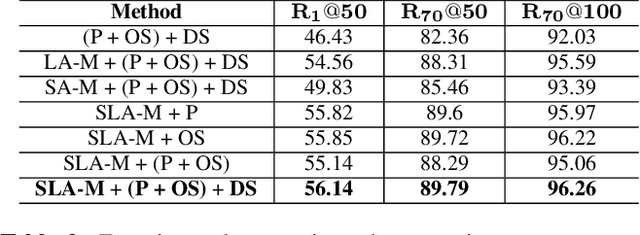
Detecting visual relationships, i.e. <Subject, Predicate, Object> triplets, is a challenging Scene Understanding task approached in the past via linguistic priors or spatial information in a single feature branch. We introduce a new deeply supervised two-branch architecture, the Multimodal Attentional Translation Embeddings, where the visual features of each branch are driven by a multimodal attentional mechanism that exploits spatio-linguistic similarities in a low-dimensional space. We present a variety of experiments comparing against all related approaches in the literature, as well as by re-implementing and fine-tuning several of them. Results on the commonly employed VRD dataset [1] show that the proposed method clearly outperforms all others, while we also justify our claims both quantitatively and qualitatively.