 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTwo New Evaluation Datasets for Low-Resource Machine Translation: Nepali-English and Sinhala-English
Paper and Code
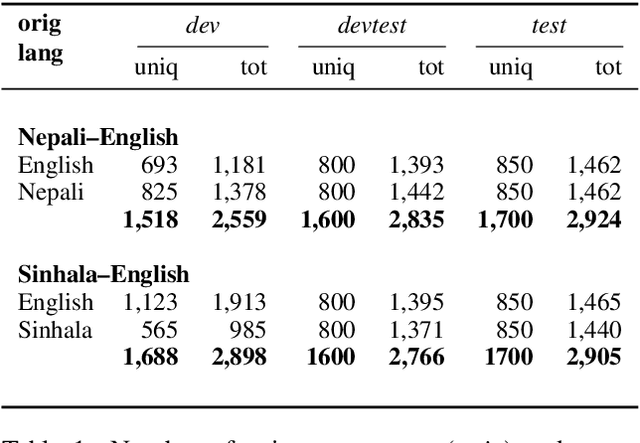
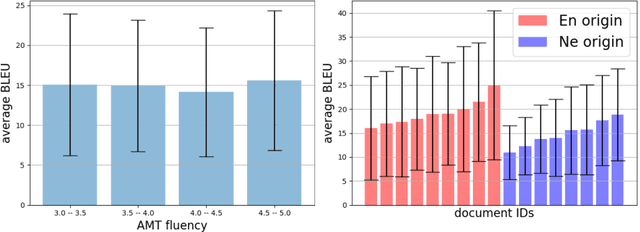
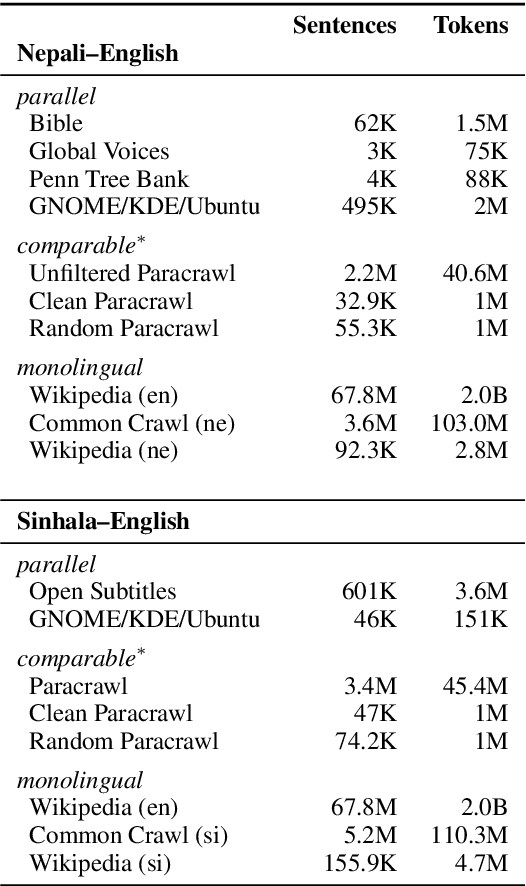
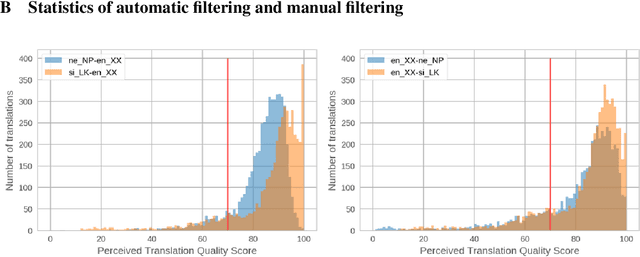
The vast majority of language pairs in the world are low-resource because they have little, if any, parallel data available. Unfortunately, machine translation (MT) systems do not currently work well in this setting. Besides the technical challenges of learning with limited supervision, there is also another challenge: it is very difficult to evaluate methods trained on low resource language pairs because there are very few freely and publicly available benchmarks. In this work, we take sentences from Wikipedia pages and introduce new evaluation datasets in two very low resource language pairs, Nepali-English and Sinhala-English. These are languages with very different morphology and syntax, for which little out-of-domain parallel data is available and for which relatively large amounts of monolingual data are freely available. We describe our process to collect and cross-check the quality of translations, and we report baseline performance using several learning settings: fully supervised, weakly supervised, semi-supervised, and fully unsupervised. Our experiments demonstrate that current state-of-the-art methods perform rather poorly on this benchmark, posing a challenge to the research community working on low resource MT. Data and code to reproduce our experiments are available at https://github.com/facebookresearch/flores.