 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDepthwise Convolution is All You Need for Learning Multiple Visual Domains
Paper and Code
Feb 19, 2019

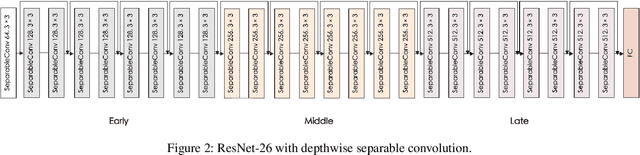
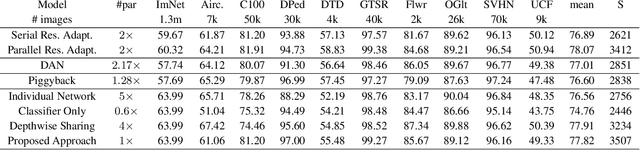
There is a growing interest in designing models that can deal with images from different visual domains. If there exists a universal structure in different visual domains that can be captured via a common parameterization, then we can use a single model for all domains rather than one model per domain. A model aware of the relationships between different domains can also be trained to work on new domains with less resources. However, to identify the reusable structure in a model is not easy. In this paper, we propose a multi-domain learning architecture based on depthwise separable convolution. The proposed approach is based on the assumption that images from different domains share cross-channel correlations but have domain-specific spatial correlations. The proposed model is compact and has minimal overhead when being applied to new domains. Additionally, we introduce a gating mechanism to promote soft sharing between different domains. We evaluate our approach on Visual Decathlon Challenge, a benchmark for testing the ability of multi-domain models. The experiments show that our approach can achieve the highest score while only requiring 50% of the parameters compared with the state-of-the-art approaches.