 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Supervised Visual Representations for Cross-Modal Retrieval
Paper and Code
Jan 31, 2019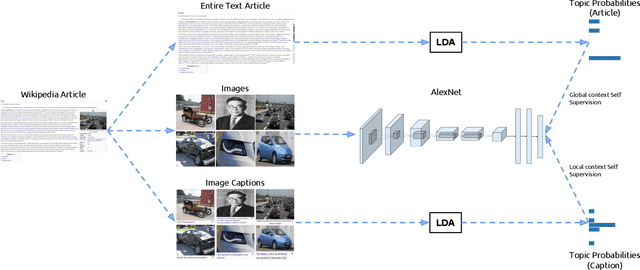
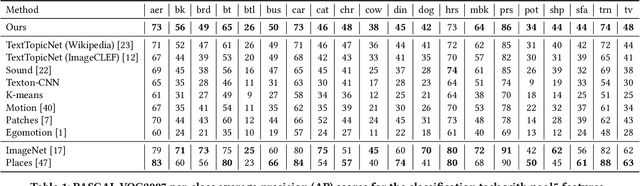

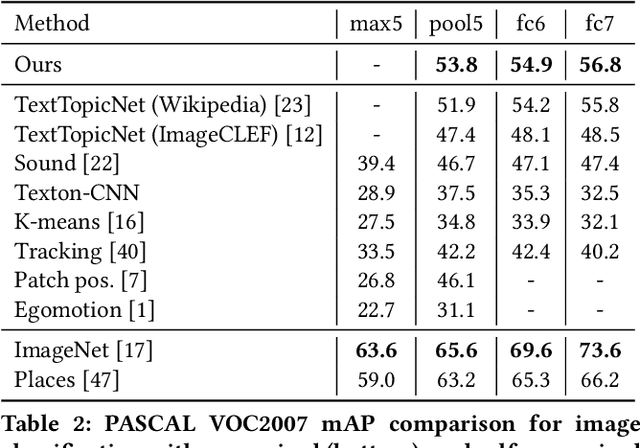
Cross-modal retrieval methods have been significantly improved in last years with the use of deep neural networks and large-scale annotated datasets such as ImageNet and Places. However, collecting and annotating such datasets requires a tremendous amount of human effort and, besides, their annotations are usually limited to discrete sets of popular visual classes that may not be representative of the richer semantics found on large-scale cross-modal retrieval datasets. In this paper, we present a self-supervised cross-modal retrieval framework that leverages as training data the correlations between images and text on the entire set of Wikipedia articles. Our method consists in training a CNN to predict: (1) the semantic context of the article in which an image is more probable to appear as an illustration (global context), and (2) the semantic context of its caption (local context). Our experiments demonstrate that the proposed method is not only capable of learning discriminative visual representations for solving vision tasks like image classification and object detection, but that the learned representations are better for cross-modal retrieval when compared to supervised pre-training of the network on the ImageNet dataset.