 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNoise-tolerant fair classification
Paper and Code

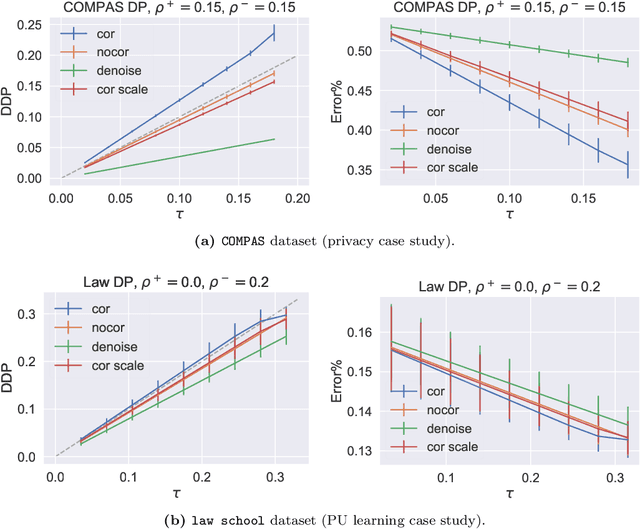
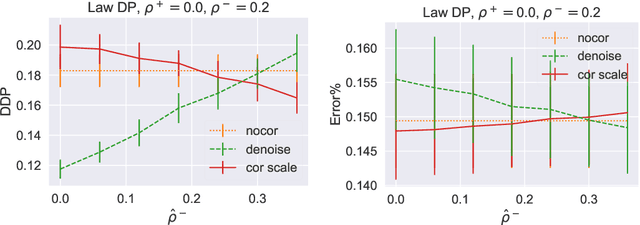

Fair machine learning concerns the analysis and design of learning algorithms that do not exhibit systematic bias with respect to some sensitive feature (e.g., race, gender). This subject has received sustained interest in the past few years, with considerable progress on both devising sensible measures of fairness, and means of achieving them. Typically, the latter involves correcting one's learning procedure so that there is no bias on the training sample. However, all such work has operated under the assumption that the sensitive feature available in one's training sample is perfectly reliable. This assumption may be violated in many real-world cases: for example, respondents to a survey may choose to conceal or obfuscate their group identity out of privacy concerns. This poses the question of whether one can still learn fair classifiers in the presence of such noisy sensitive features. In this paper, we answer the question in the affirmative for a widely-used measure of fairness and model of noise. We show that if one measures fairness using the mean-difference score, and sensitive features are subject to noise from the mutually contaminated learning model, then owing to a simple identity we only need to change the desired fairness-tolerance. The requisite tolerance can be estimated by leveraging existing noise-rate estimators. We finally show that our procedure is empirically effective on two case-studies involving sensitive feature censoring.