 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating Generalization Ability of Convolutional Neural Networks and Capsule Networks for Image Classification via Top-2 Classification
Paper and Code
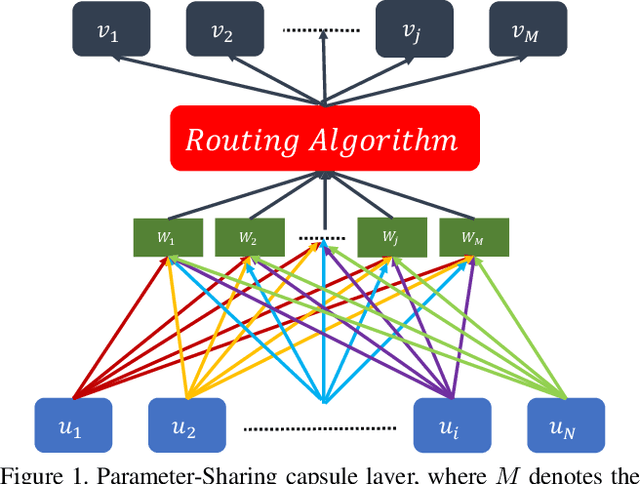
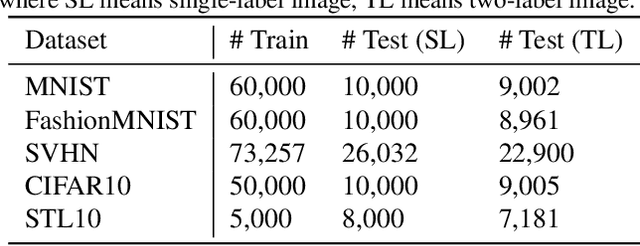


Image classification is a challenging problem which aims to identify the category of object in the image. In recent years, deep Convolutional Neural Networks (CNNs) have been applied to handle this task, and impressive improvement has been achieved. However, some research showed the output of CNNs can be easily altered by adding relatively small perturbations to the input image, such as modifying few pixels. Recently, Capsule Networks (CapsNets) are proposed, which can help eliminating this limitation. Experiments on MNIST dataset revealed that capsules can better characterize the features of object than CNNs. But it's hard to find a suitable quantitative method to compare the generalization ability of CNNs and CapsNets. In this paper, we propose a new image classification task called Top-2 classification to evaluate the generalization ability of CNNs and CapsNets. The models are trained on single label image samples same as the traditional image classification task. But in the test stage, we randomly concatenate two test image samples which contain different labels, and then use the trained models to predict the top-2 labels on the unseen newly-created two label image samples. This task can provide us precise quantitative results to compare the generalization ability of CNNs and CapsNets. Back to the CapsNet, because it uses Full Connectivity (FC) mechanism among all capsules, it requires many parameters. To reduce the number of parameters, we introduce the Parameter-Sharing (PS) mechanism between capsules. Experiments on five widely used benchmark image datasets demonstrate the method significantly reduces the number of parameters, without losing the effectiveness of extracting features. Further, on the Top-2 classification task, the proposed PS CapsNets obtain impressive higher accuracy compared to the traditional CNNs and FC CapsNets by a large margin.