 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComplexity of Linear Regions in Deep Networks
Paper and Code
Jan 25, 2019
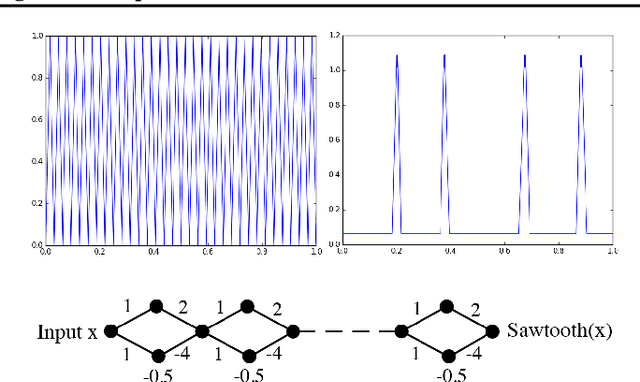
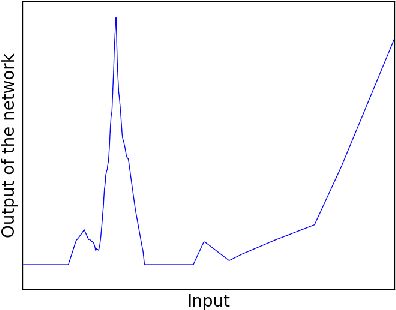
It is well-known that the expressivity of a neural network depends on its architecture, with deeper networks expressing more complex functions. In the case of networks that compute piecewise linear functions, such as those with ReLU activation, the number of distinct linear regions is a natural measure of expressivity. It is possible to construct networks for which the number of linear regions grows exponentially with depth, or with merely a single region; it is not clear where within this range most networks fall in practice, either before or after training. In this paper, we provide a mathematical framework to count the number of linear regions of a piecewise linear network and measure the volume of the boundaries between these regions. In particular, we prove that for networks at initialization, the average number of regions along any one-dimensional subspace grows linearly in the total number of neurons, far below the exponential upper bound. We also find that the average distance to the nearest region boundary at initialization scales like the inverse of the number of neurons. Our theory suggests that, even after training, the number of linear regions is far below exponential, an intuition that matches our empirical observations. We conclude that the practical expressivity of neural networks is likely far below that of the theoretical maximum, and that this gap can be quantified.