 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemi-Supervised Image-to-Image Translation
Paper and Code
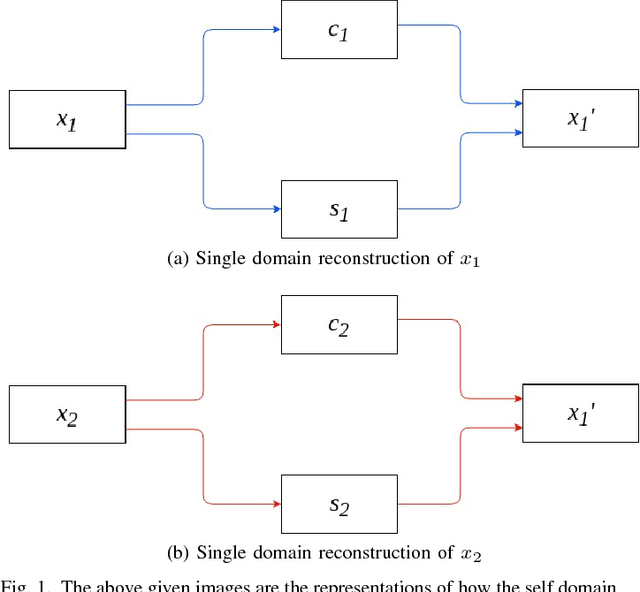
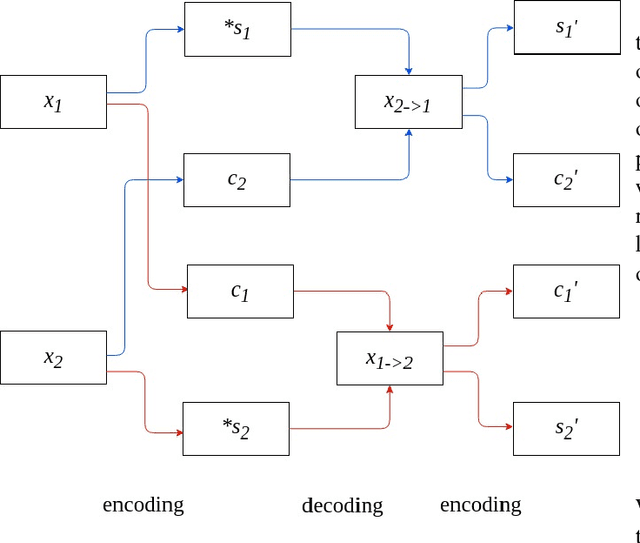
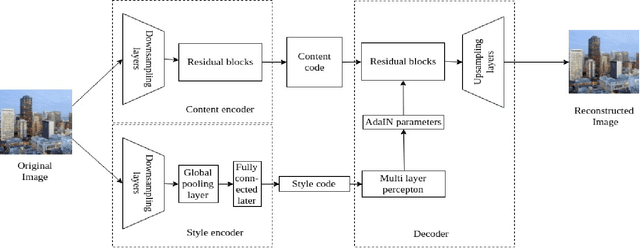

Image-to-image translation is a long-established and a difficult problem in computer vision. In this paper we propose an adversarial based model for image-to-image translation. The regular deep neural-network based methods perform the task of image-to-image translation by comparing gram matrices and using image segmentation which requires human intervention. Our generative adversarial network based model works on a conditional probability approach. This approach makes the image translation independent of any local, global and content or style features. In our approach we use a bidirectional reconstruction model appended with the affine transform factor that helps in conserving the content and photorealism as compared to other models. The advantage of using such an approach is that the image-to-image translation is semi-supervised, independant of image segmentation and inherits the properties of generative adversarial networks tending to produce realistic. This method has proven to produce better results than Multimodal Unsupervised Image-to-image translation.