 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNormalizing Text using Language Modelling based on Phonetics and String Similarity
Jun 25, 2020
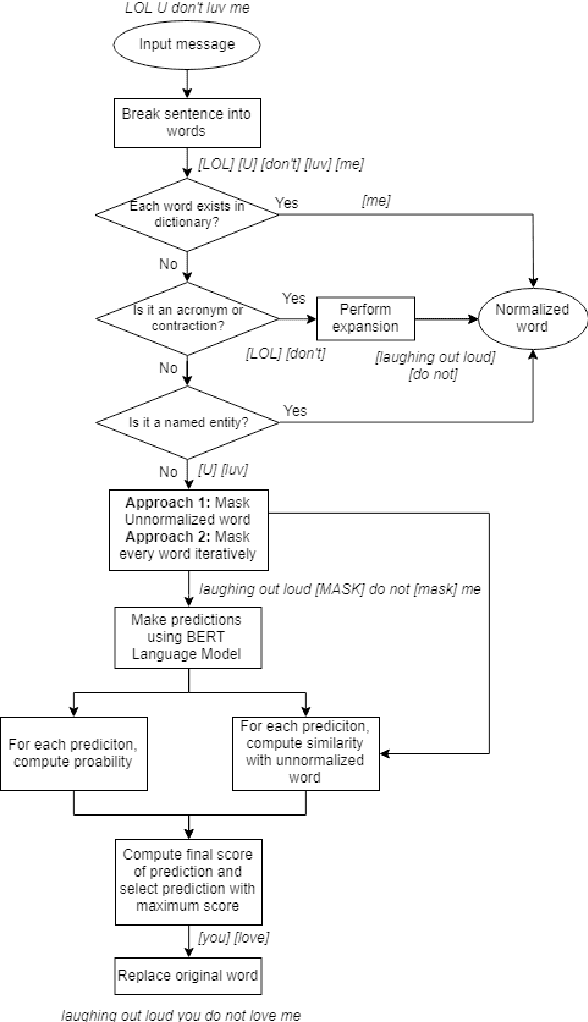

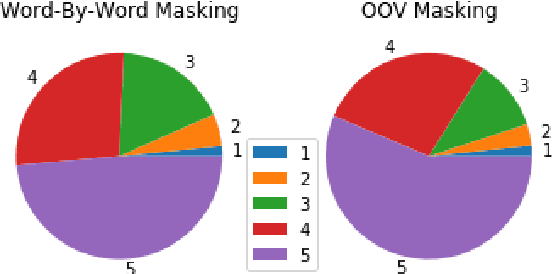
Social media networks and chatting platforms often use an informal version of natural text. Adversarial spelling attacks also tend to alter the input text by modifying the characters in the text. Normalizing these texts is an essential step for various applications like language translation and text to speech synthesis where the models are trained over clean regular English language. We propose a new robust model to perform text normalization. Our system uses the BERT language model to predict the masked words that correspond to the unnormalized words. We propose two unique masking strategies that try to replace the unnormalized words in the text with their root form using a unique score based on phonetic and string similarity metrics.We use human-centric evaluations where volunteers were asked to rank the normalized text. Our strategies yield an accuracy of 86.7% and 83.2% which indicates the effectiveness of our system in dealing with text normalization.
MREAK : Morphological Retina Keypoint Descriptor
Jan 24, 2019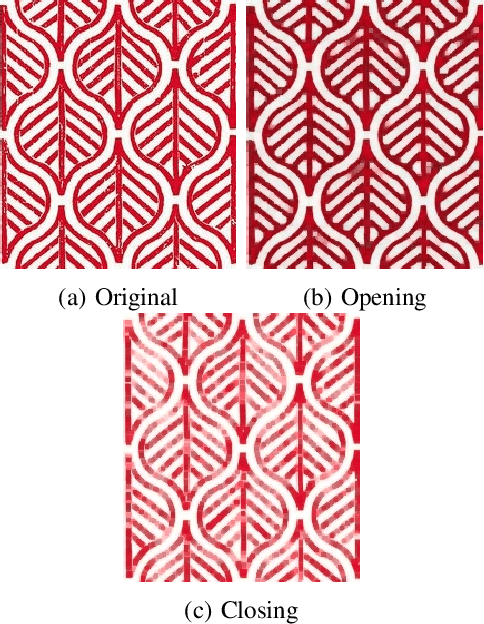
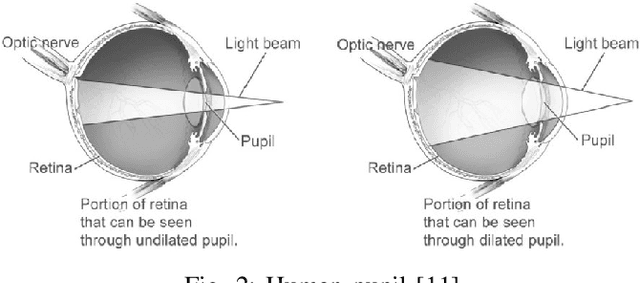
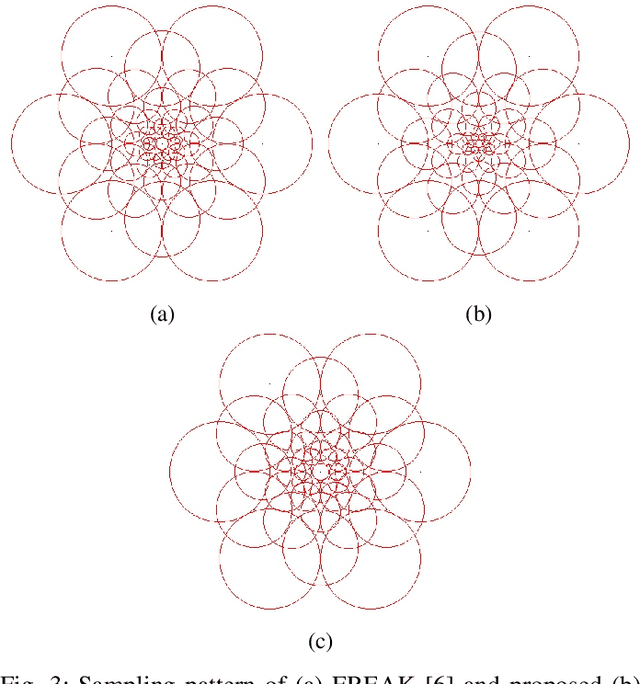
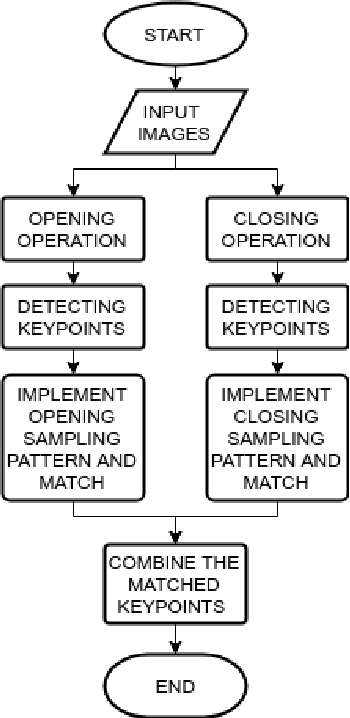
A variety of computer vision applications depend on the efficiency of image matching algorithms used. Various descriptors are designed to detect and match features in images. Deployment of this algorithms in mobile applications creates a need for low computation time. Binary descriptors requires less computation time than float-point based descriptors because of the intensity comparison between pairs of sample points and comparing after creating a binary string. In order to decrease time complexity, quality of keypoints matched is often compromised. We propose a keypoint descriptor named Morphological Retina Keypoint Descriptor (MREAK) inspired by the function of human pupil which dilates and constricts responding to the amount of light. By using morphological operators of opening and closing and modifying the retinal sampling pattern accordingly, an increase in the number of accurately matched keypoints is observed. Our results show that matched keypoints are more efficient than FREAK descriptor and requires low computation time than various descriptors like SIFT, BRISK and SURF.
Semi-Supervised Image-to-Image Translation
Jan 24, 2019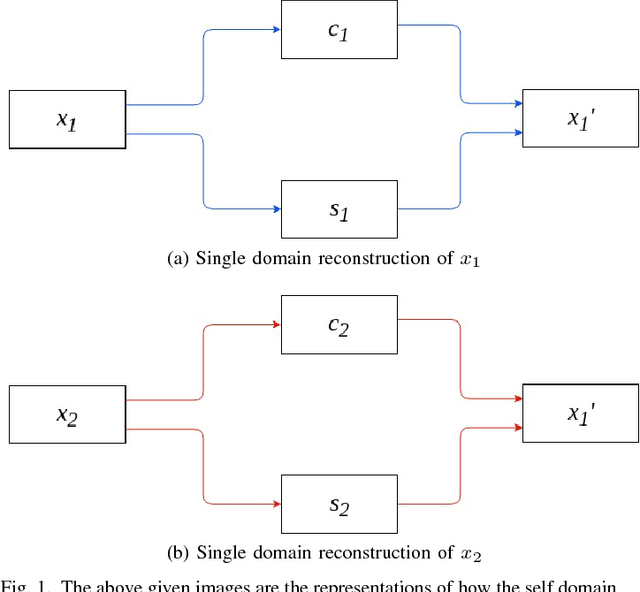
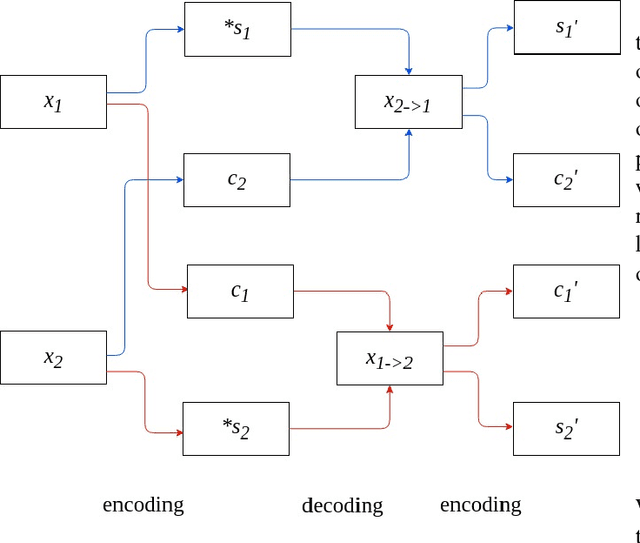
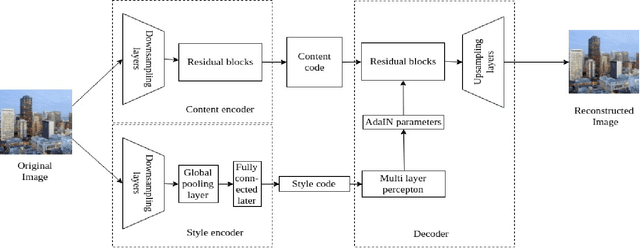

Image-to-image translation is a long-established and a difficult problem in computer vision. In this paper we propose an adversarial based model for image-to-image translation. The regular deep neural-network based methods perform the task of image-to-image translation by comparing gram matrices and using image segmentation which requires human intervention. Our generative adversarial network based model works on a conditional probability approach. This approach makes the image translation independent of any local, global and content or style features. In our approach we use a bidirectional reconstruction model appended with the affine transform factor that helps in conserving the content and photorealism as compared to other models. The advantage of using such an approach is that the image-to-image translation is semi-supervised, independant of image segmentation and inherits the properties of generative adversarial networks tending to produce realistic. This method has proven to produce better results than Multimodal Unsupervised Image-to-image translation.
Acronym Disambiguation: A Domain Independent Approach
Dec 17, 2017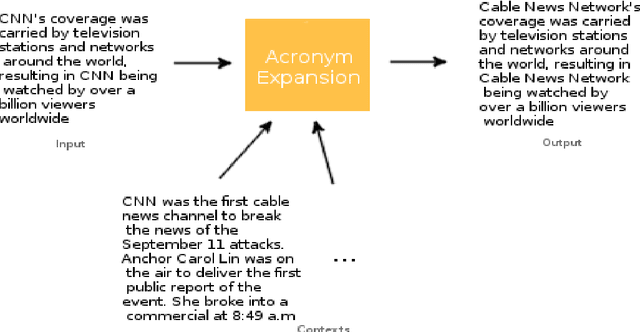
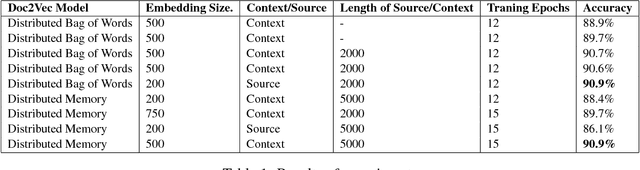

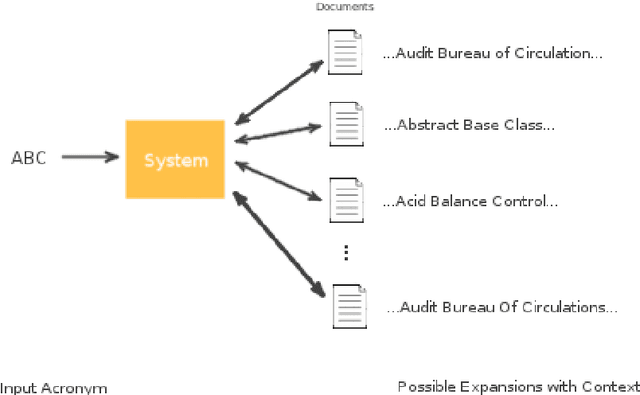
Acronyms are omnipresent. They usually express information that is repetitive and well known. But acronyms can also be ambiguous because there can be multiple expansions for the same acronym. In this paper, we propose a general system for acronym disambiguation that can work on any acronym given some context information. We present methods for retrieving all the possible expansions of an acronym from Wikipedia and AcronymsFinder.com. We propose to use these expansions to collect all possible contexts in which these acronyms are used and then score them using a paragraph embedding technique called Doc2Vec. This method collectively led to achieving an accuracy of 90.9% in selecting the correct expansion for given acronym, on a dataset we scraped from Wikipedia with 707 distinct acronyms and 14,876 disambiguations.