 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerating Textual Adversarial Examples for Deep Learning Models: A Survey
Paper and Code
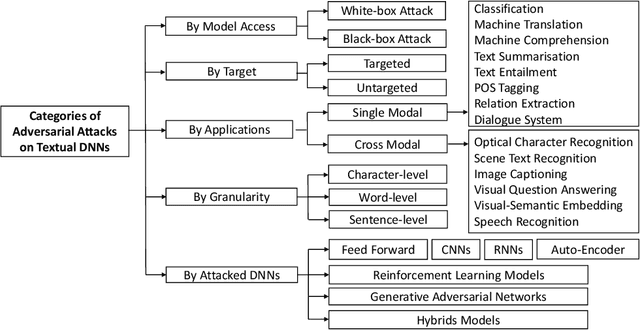
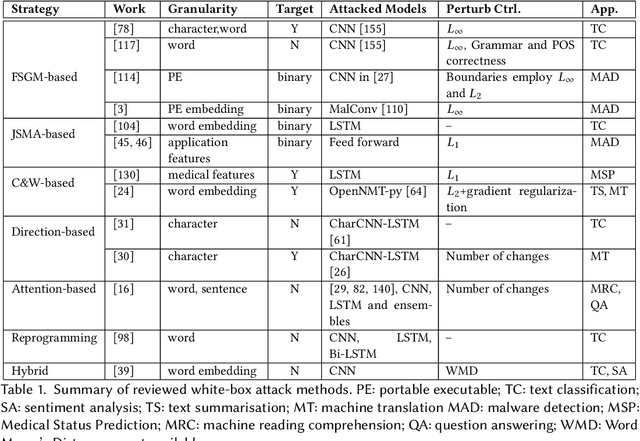
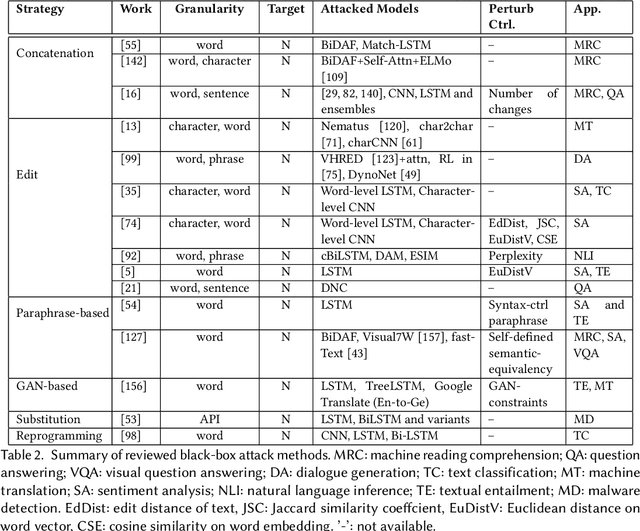
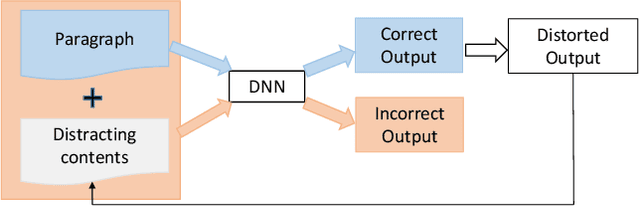
With the development of high computational devices, deep neural networks (DNNs), in recent years, have gained significant popularity in many Artificial Intelligence (AI) applications. However, previous efforts have shown that DNNs were vulnerable to strategically modified samples, named adversarial examples. These samples are generated with some imperceptible perturbations but can fool the DNNs to give false predictions. Inspired by the popularity of generating adversarial examples for image DNNs, research efforts on attacking DNNs for textual applications emerges in recent years. However, existing perturbation methods for images cannotbe directly applied to texts as text data is discrete. In this article, we review research works that address this difference and generatetextual adversarial examples on DNNs. We collect, select, summarize, discuss and analyze these works in a comprehensive way andcover all the related information to make the article self-contained. Finally, drawing on the reviewed literature, we provide further discussions and suggestions on this topic.