 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Benefits of Over-parameterization at Initialization in Deep ReLU Networks
Paper and Code
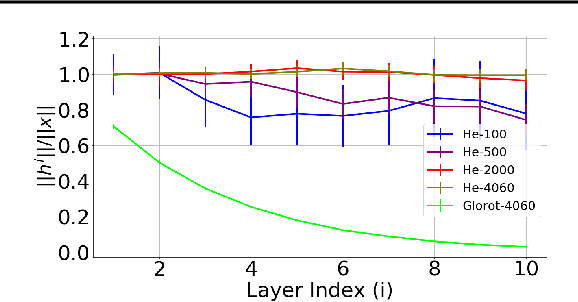
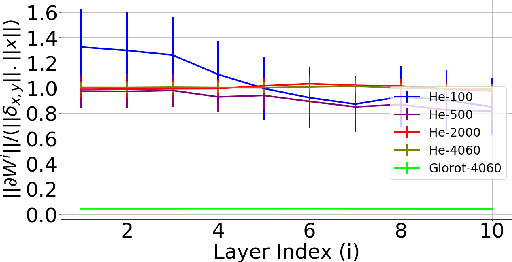
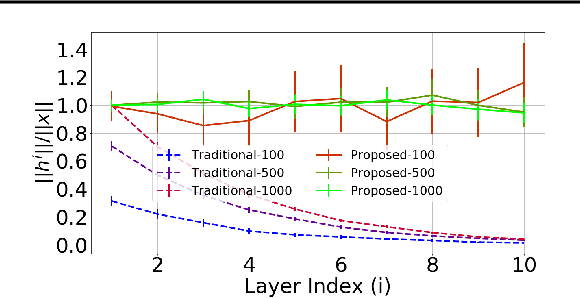
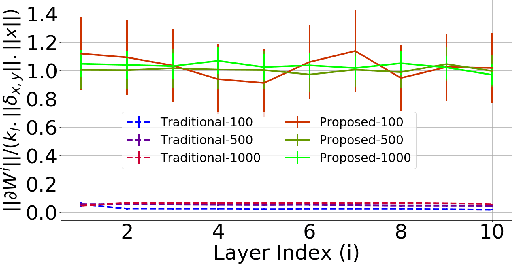
It has been noted in existing literature that over-parameterization in ReLU networks generally leads to better performance. While there could be several reasons for this, we investigate desirable network properties at initialization which may be enjoyed by ReLU networks. Without making any assumption, we derive a lower bound on the layer width of deep ReLU networks whose weights are initialized from a certain distribution, such that with high probability, i) the norm of hidden activation of all layers are roughly equal to the norm of the input, and, ii) the norm of parameter gradient for all the layers are roughly the same. In this way, sufficiently wide deep ReLU nets with appropriate initialization can inherently preserve the forward flow of information and also avoid the gradient exploding/vanishing problem. We further show that these results hold for an infinite number of data samples, in which case the finite lower bound depends on the input dimensionality and the depth of the network. In the case of deep ReLU networks with weight vectors normalized by their norm, we derive an initialization required to tap the aforementioned benefits from over-parameterization without which network fails to learn for large depth.