 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Semantic Multimodal Hashing Network for Scalable Multimedia Retrieval
Paper and Code
Jan 09, 2019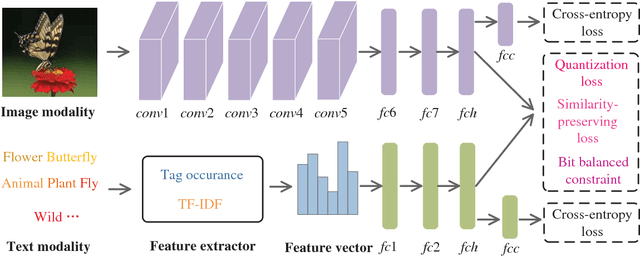
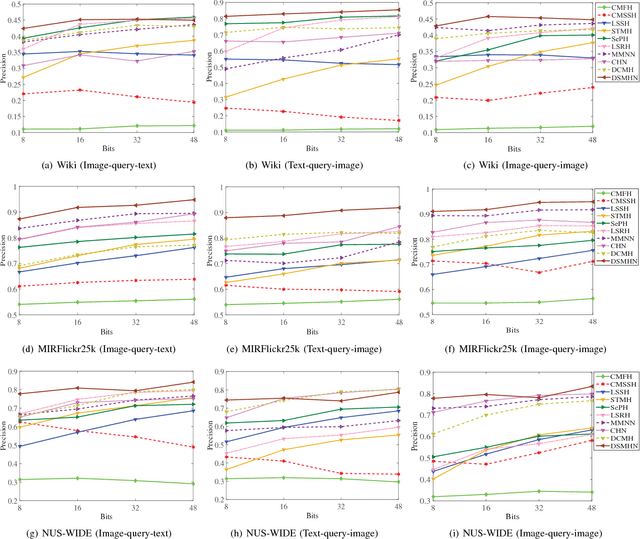
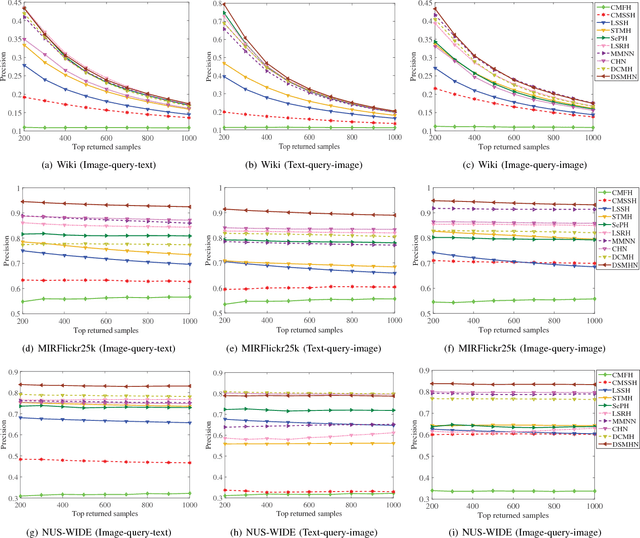
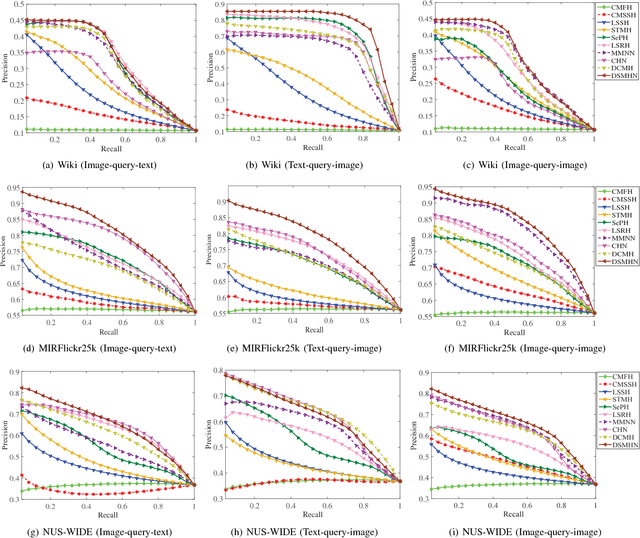
Hashing has been widely applied to multimodal retrieval on large-scale multimedia data due to its efficiency in computation and storage. Particularly, deep hashing has received unprecedented research attention in recent years, owing to its perfect retrieval performance. However, most of existing deep hashing methods learn binary hash codes by preserving the similarity relationship while without exploiting the semantic labels, which result in suboptimal binary codes. In this work, we propose a novel Deep Semantic Multimodal Hashing Network (DSMHN) for scalable multimodal retrieval. In DSMHN, two sets of modality-specific hash functions are jointly learned by explicitly preserving both the inter-modality similarities and the intra-modality semantic labels. Specifically, with the assumption that the learned hash codes should be optimal for task-specific classification, two stream networks are jointly trained to learn the hash functions by embedding the semantic labels on the resultant hash codes. Different from previous deep hashing methods, which are tied to some particular forms of loss functions, our deep hashing framework can be flexibly integrated with different types of loss functions. In addition, the bit balance property is investigated to generate binary codes with each bit having $50\%$ probability to be $1$ or $-1$. Moreover, a unified deep multimodal hashing framework is proposed to learn compact and high-quality hash codes by exploiting the feature representation learning, inter-modality similarity preserving learning, semantic label preserving learning and hash functions learning with bit balanced constraint simultaneously. We conduct extensive experiments for both unimodal and cross-modal retrieval tasks on three widely-used multimodal retrieval datasets. The experimental result demonstrates that DSMHN significantly outperforms state-of-the-art methods.