 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLocation-Centered House Price Prediction: A Multi-Task Learning Approach
Paper and Code
Jan 07, 2019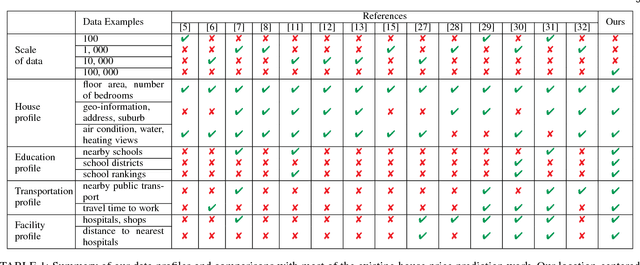
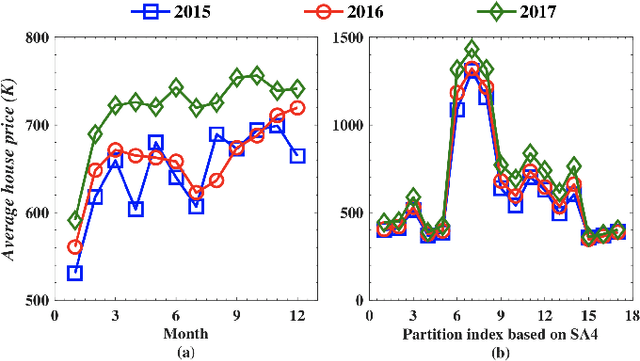
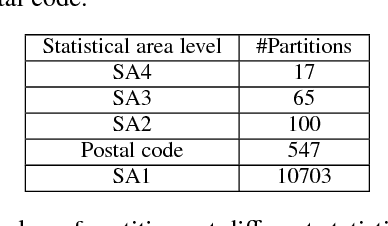
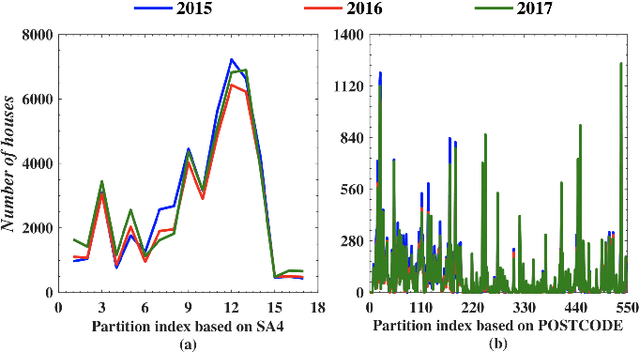
Accurate house prediction is of great significance to various real estate stakeholders such as house owners, buyers, investors, and agents. We propose a location-centered prediction framework that differs from existing work in terms of data profiling and prediction model. Regarding data profiling, we define and capture a fine-grained location profile powered by a diverse range of location data sources, such as transportation profile (e.g., distance to nearest train station), education profile (e.g., school zones and ranking), suburb profile based on census data, facility profile (e.g., nearby hospitals, supermarkets). Regarding the choice of prediction model, we observe that a variety of approaches either consider the entire house data for modeling, or split the entire data and model each partition independently. However, such modeling ignores the relatedness between partitions, and for all prediction scenarios, there may not be sufficient training samples per partition for the latter approach. We address this problem by conducting a careful study of exploiting the Multi-Task Learning (MTL) model. Specifically, we map the strategies for splitting the entire house data to the ways the tasks are defined in MTL, and each partition obtained is aligned with a task. Furthermore, we select specific MTL-based methods with different regularization terms to capture and exploit the relatedness between tasks. Based on real-world house transaction data collected in Melbourne, Australia. We design extensive experimental evaluations, and the results indicate a significant superiority of MTL-based methods over state-of-the-art approaches. Meanwhile, we conduct an in-depth analysis on the impact of task definitions and method selections in MTL on the prediction performance, and demonstrate that the impact of task definitions on prediction performance far exceeds that of method selections.