 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSkeleton Transformer Networks: 3D Human Pose and Skinned Mesh from Single RGB Image
Paper and Code
Dec 29, 2018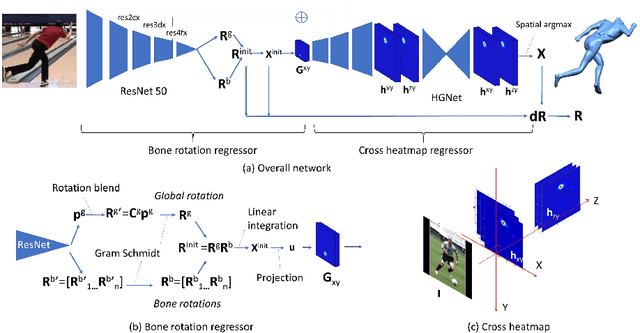
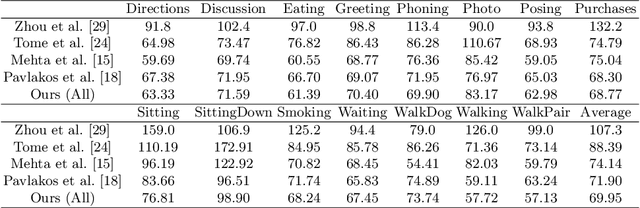


In this paper, we present Skeleton Transformer Networks (SkeletonNet), an end-to-end framework that can predict not only 3D joint positions but also 3D angular pose (bone rotations) of a human skeleton from a single color image. This in turn allows us to generate skinned mesh animations. Here, we propose a two-step regression approach. The first step regresses bone rotations in order to obtain an initial solution by considering skeleton structure. The second step performs refinement based on heatmap regressor using a 3D pose representation called cross heatmap which stacks heatmaps of xy and zy coordinates. By training the network using the proposed 3D human pose dataset that is comprised of images annotated with 3D skeletal angular poses, we showed that SkeletonNet can predict a full 3D human pose (joint positions and bone rotations) from a single image in-the-wild.