 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCross Lingual Speech Emotion Recognition: Urdu vs. Western Languages
Paper and Code
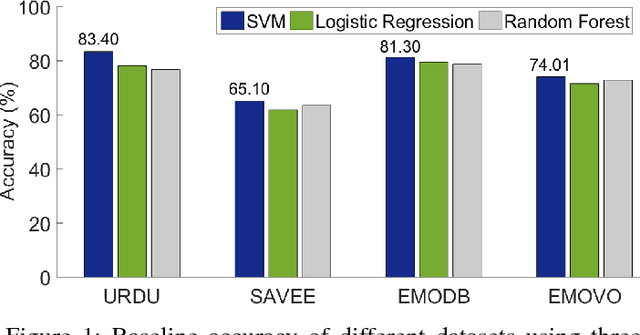
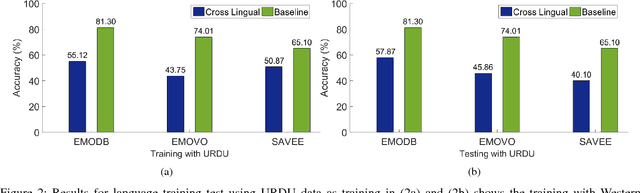
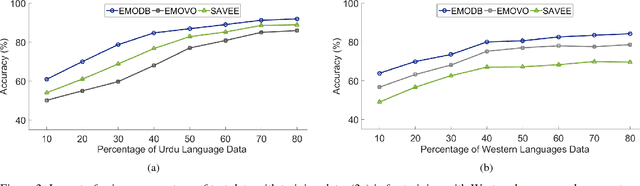
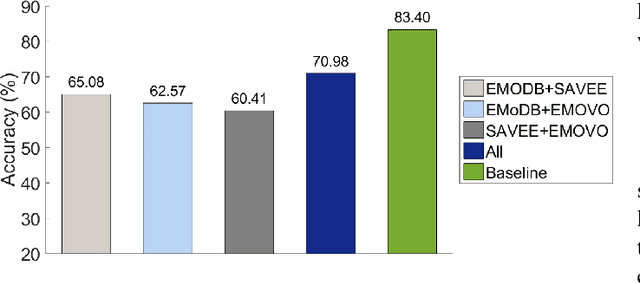
Cross-lingual speech emotion recognition is an important task for practical applications. The performance of automatic speech emotion recognition systems degrades in cross-corpus scenarios, particularly in scenarios involving multiple languages or a previously unseen language such as Urdu for which limited or no data is available. In this study, we investigate the problem of cross-lingual emotion recognition for Urdu language and contribute URDU---the first ever spontaneous Urdu-language speech emotion database. Evaluations are performed using three different Western languages against Urdu and experimental results on different possible scenarios suggest various interesting aspects for designing more adaptive emotion recognition system for such limited languages. In results, selecting training instances of multiple languages can deliver comparable results to baseline and augmentation a fraction of testing language data while training can help to boost accuracy for speech emotion recognition. URDU data is publicly available for further research.