 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploiting Cross-Lingual Subword Similarities in Low-Resource Document Classification
Paper and Code
Dec 22, 2018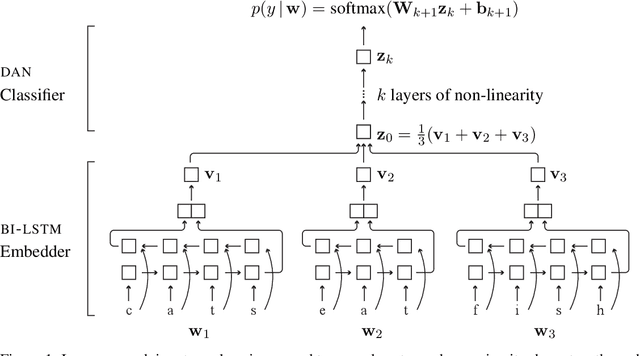
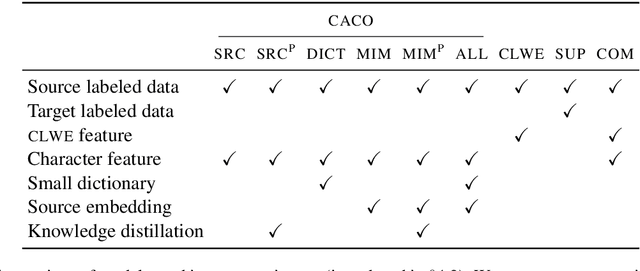
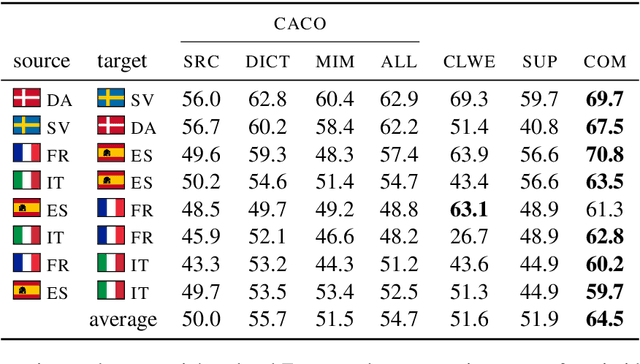
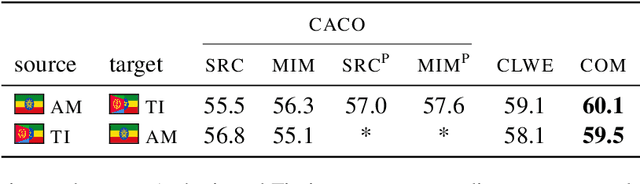
Text classification must sometimes be applied in situations with no training data in a target language. However, training data may be available in a related language. We introduce a cross-lingual document classification framework (CACO) between related language pairs. To best use limited training data, our transfer learning scheme exploits cross-lingual subword similarity by jointly training a character-based embedder and a word-based classifier. The embedder derives vector representations for input words from their written forms, and the classifier makes predictions based on the word vectors. We use a joint character representation for both the source language and the target language, which allows the embedder to generalize knowledge about source language words to target language words with similar forms. We propose a multi-task objective that can further improve the model if additional cross-lingual or monolingual resources are available. CACO models trained under low-resource settings rival cross-lingual word embedding models trained under high-resource settings on related language pairs.