Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Empirical Analysis of Deep Audio-Visual Models for Speech Recognition
Paper and Code
Dec 21, 2018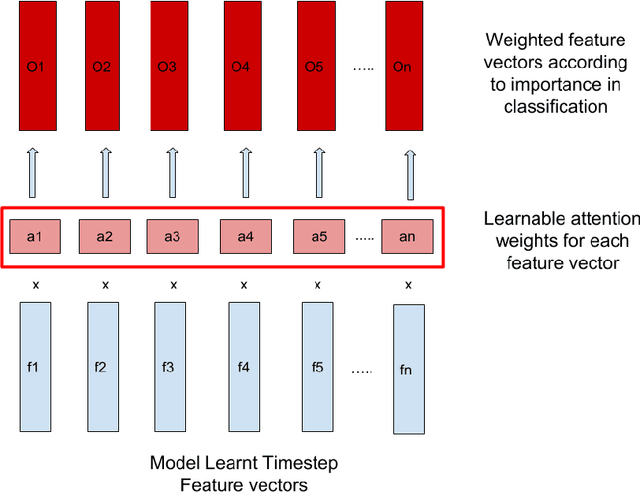

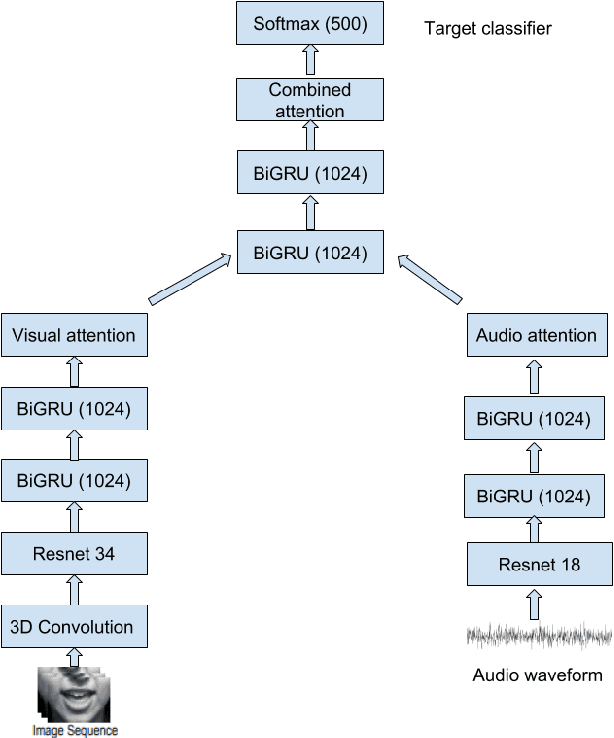
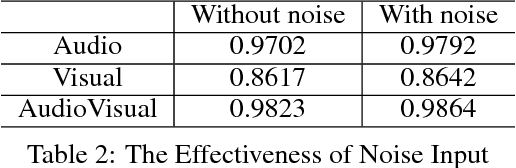
In this project, we worked on speech recognition, specifically predicting individual words based on both the video frames and audio. Empowered by convolutional neural networks, the recent speech recognition and lip reading models are comparable to human level performance. We re-implemented and made derivations of the state-of-the-art model. Then, we conducted rich experiments including the effectiveness of attention mechanism, more accurate residual network as the backbone with pre-trained weights and the sensitivity of our model with respect to audio input with/without noise.
View paper on