 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeResidual Policy Learning
Paper and Code
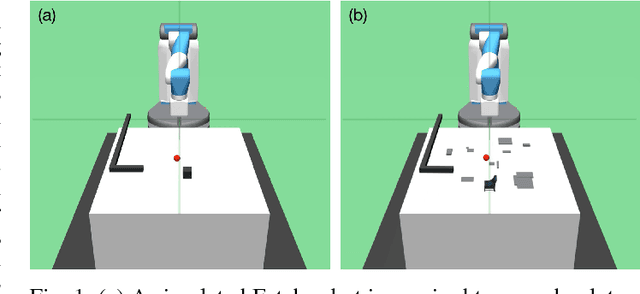
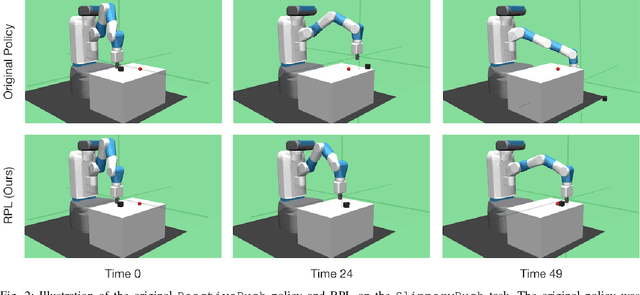
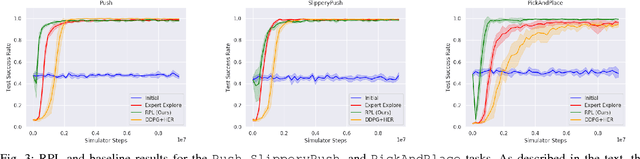
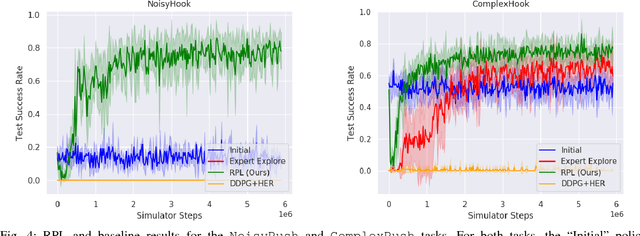
We present Residual Policy Learning (RPL): a simple method for improving nondifferentiable policies using model-free deep reinforcement learning. RPL thrives in complex robotic manipulation tasks where good but imperfect controllers are available. In these tasks, reinforcement learning from scratch remains data-inefficient or intractable, but learning a residual on top of the initial controller can yield substantial improvements. We study RPL in six challenging MuJoCo tasks involving partial observability, sensor noise, model misspecification, and controller miscalibration. For initial controllers, we consider both hand-designed policies and model-predictive controllers with known or learned transition models. By combining learning with control algorithms, RPL can perform long-horizon, sparse-reward tasks for which reinforcement learning alone fails. Moreover, we find that RPL consistently and substantially improves on the initial controllers. We argue that RPL is a promising approach for combining the complementary strengths of deep reinforcement learning and robotic control, pushing the boundaries of what either can achieve independently. Video and code at https://k-r-allen.github.io/residual-policy-learning/.