 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCooperative Multi-Agent Policy Gradients with Sub-optimal Demonstration
Paper and Code
Dec 05, 2018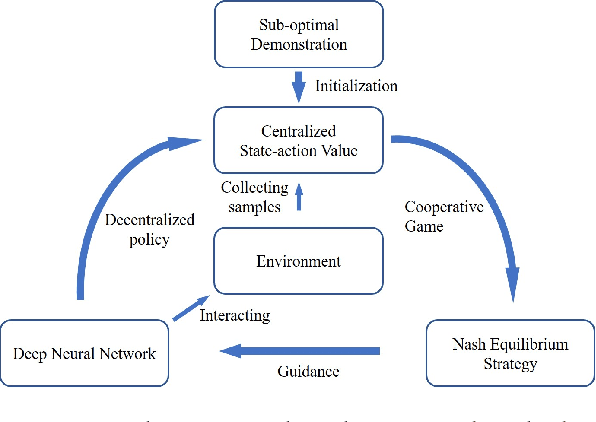
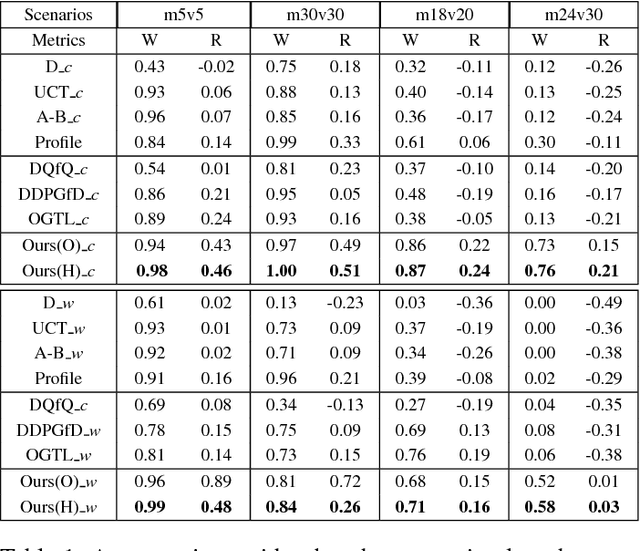
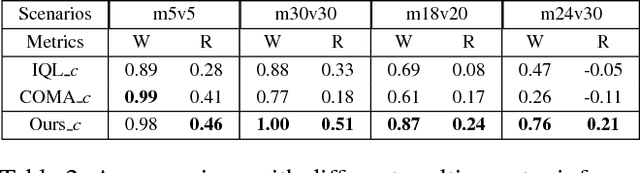

Many reality tasks such as robot coordination can be naturally modelled as multi-agent cooperative system where the rewards are sparse. This paper focuses on learning decentralized policies for such tasks using sub-optimal demonstration. To learn the multi-agent cooperation effectively and tackle the sub-optimality of demonstration, a self-improving learning method is proposed: On the one hand, the centralized state-action values are initialized by the demonstration and updated by the learned decentralized policy to improve the sub-optimality. On the other hand, the Nash Equilibrium are found by the current state-action value and are used as a guide to learn the policy. The proposed method is evaluated on the combat RTS games which requires a high level of multi-agent cooperation. Extensive experimental results on various combat scenarios demonstrate that the proposed method can learn multi-agent cooperation effectively. It significantly outperforms many state-of-the-art demonstration based approaches.