 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerating Diverse Programs with Instruction Conditioned Reinforced Adversarial Learning
Paper and Code
Dec 03, 2018

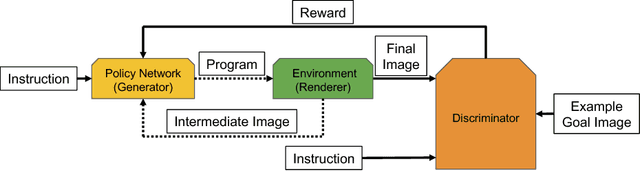
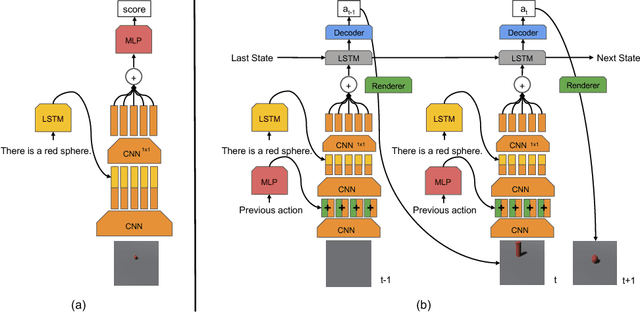
Advances in Deep Reinforcement Learning have led to agents that perform well across a variety of sensory-motor domains. In this work, we study the setting in which an agent must learn to generate programs for diverse scenes conditioned on a given symbolic instruction. Final goals are specified to our agent via images of the scenes. A symbolic instruction consistent with the goal images is used as the conditioning input for our policies. Since a single instruction corresponds to a diverse set of different but still consistent end-goal images, the agent needs to learn to generate a distribution over programs given an instruction. We demonstrate that with simple changes to the reinforced adversarial learning objective, we can learn instruction conditioned policies to achieve the corresponding diverse set of goals. Most importantly, our agent's stochastic policy is shown to more accurately capture the diversity in the goal distribution than a fixed pixel-based reward function baseline. We demonstrate the efficacy of our approach on two domains: (1) drawing MNIST digits with a paint software conditioned on instructions and (2) constructing scenes in a 3D editor that satisfies a certain instruction.