 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAsyncQVI: Asynchronous-Parallel Q-Value Iteration for Reinforcement Learning with Near-Optimal Sample Complexity
Paper and Code

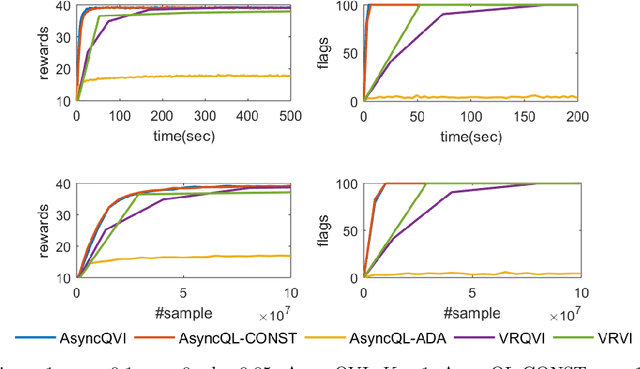

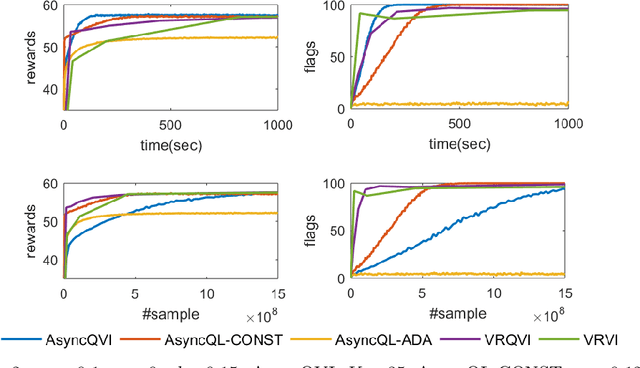
In this paper, we propose AsyncQVI: Asynchronous-Parallel Q-value Iteration to solve Reinforcement Learning (RL) problems. Given an RL problem with $|\mathcal{S}|$ states, $|\mathcal{A}|$ actions, and a discounted factor $\gamma\in(0,1)$, AsyncQVI returns an $\varepsilon$-optimal policy with probability at least $1-\delta$ at the sample complexity $$\tilde{\mathcal{O}}\bigg(\frac{|\mathcal{S}||\mathcal{A}|}{(1-\gamma)^5\varepsilon^2}\log\Big(\frac{1}{\delta}\Big)\bigg).$$ AsyncQVI is the first asynchronous-parallel RL algorithm with convergence rate analysis and an explicit sample complexity. The above sample complexity of AsyncQVI nearly matches the lower bound. Furthermore, AsyncQVI is scalable since it has low memory footprint at $\mathcal{O}(|\mathcal{S}|)$ and also has an efficient asynchronous-parallel implementation.