 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow to Make a BLT Sandwich? Learning to Reason towards Understanding Web Instructional Videos
Paper and Code
Dec 06, 2018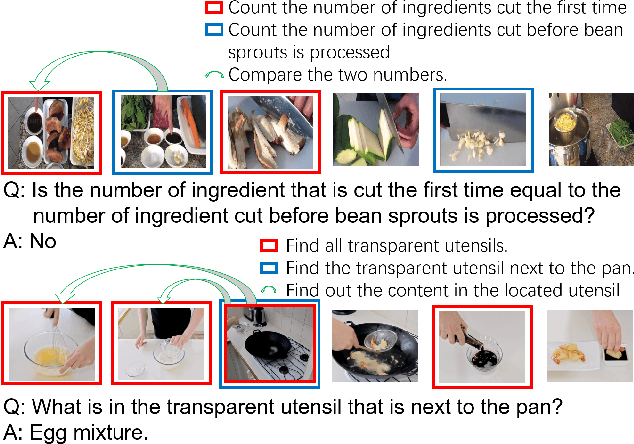
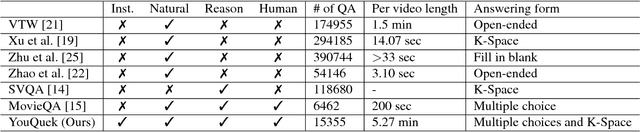
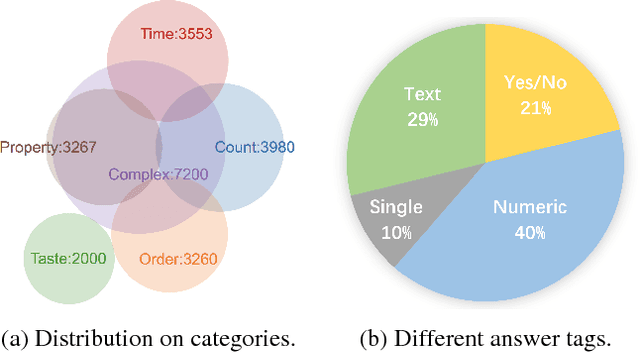
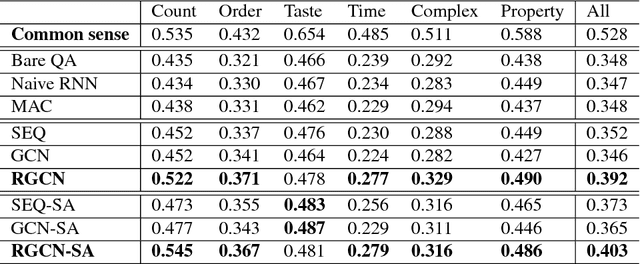
Understanding web instructional videos is an essential branch of video understanding in two aspects. First, most existing video methods focus on short-term actions for a-few-second-long video clips; these methods are not directly applicable to long videos. Second, unlike unconstrained long videos, e.g., movies, instructional videos are more structured in that they have step-by-step procedure constraining the understanding task. In this paper, we study reasoning on instructional videos via question-answering (QA). Surprisingly, it has not been an emphasis in the video community despite its rich applications. We thereby introduce YouQuek, an annotated QA dataset for instructional videos based on the recent YouCook2. The questions in YouQuek are not limited to cues on one frame but related to logical reasoning in the temporal dimension. Observing the lack of effective representations for modeling long videos, we propose a set of carefully designed models including a novel Recurrent Graph Convolutional Network (RGCN) that captures both temporal order and relation information. Furthermore, we study multiple modalities including description and transcripts for the purpose of boosting video understanding. Extensive experiments on YouQuek suggest that RGCN performs the best in terms of QA accuracy and a better performance is gained by introducing human annotated description.