 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProxylessNAS: Direct Neural Architecture Search on Target Task and Hardware
Paper and Code
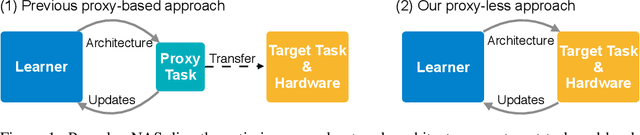
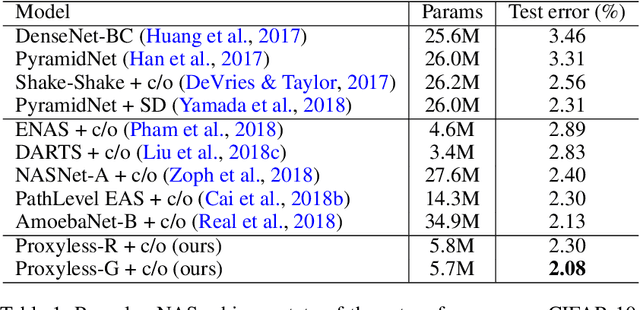
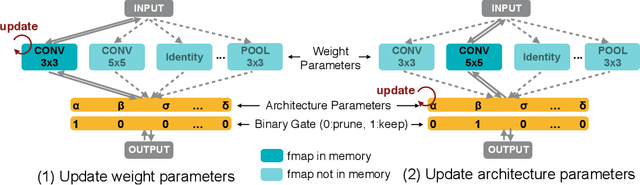
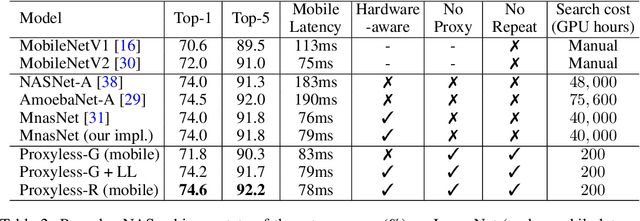
Neural architecture search (NAS) has a great impact by automatically designing effective neural network architectures. However, the prohibitive computational demand of conventional NAS algorithms (e.g. $10^4$ GPU hours) makes it difficult to \emph{directly} search the architectures on large-scale tasks (e.g. ImageNet). Differentiable NAS can reduce the cost of GPU hours via a continuous representation of network architecture but suffers from the high GPU memory consumption issue (grow linearly w.r.t. candidate set size). As a result, they need to utilize~\emph{proxy} tasks, such as training on a smaller dataset, or learning with only a few blocks, or training just for a few epochs. These architectures optimized on proxy tasks are not guaranteed to be optimal on target task. In this paper, we present \emph{ProxylessNAS} that can \emph{directly} learn the architectures for large-scale target tasks and target hardware platforms. We address the high memory consumption issue of differentiable NAS and reduce the computational cost (GPU hours and GPU memory) to the same level of regular training while still allowing a large candidate set. Experiments on CIFAR-10 and ImageNet demonstrate the effectiveness of directness and specialization. On CIFAR-10, our model achieves 2.08\% test error with only 5.7M parameters, better than the previous state-of-the-art architecture AmoebaNet-B, while using 6$\times$ fewer parameters. On ImageNet, our model achieves 3.1\% better top-1 accuracy than MobileNetV2, while being 1.2$\times$ faster with measured GPU latency. We also apply ProxylessNAS to specialize neural architectures for hardware with direct hardware metrics (e.g. latency) and provide insights for efficient CNN architecture design.